部分内容来自https://www.zhihu.com/question/11467407313/answer/94584520134
问题一:真的只用花 50 美元吗?
如果只考虑最后一轮成功微调训练出 s1 模型所消耗的 GPU 卡时,是的,甚至更少。论文中说 s1 模型的训练卡时只需要 7 H100 卡时,作者对媒体说的原话是「可以用 20 美元在云平台上租到这些算力」。
关于这里的成本,我觉得有三点需要说明:
- s1 模型是基于 Qwen2.5-32B-Instruct 模型使用 1000 条数据进行的 SFT 微调,而非从头开始的模型训练(想想也不可能);
- 正如 DeepSeek V3 的 557.6 万美元训练成本一样,这里的成本只包括训练时的 GPU 算力费用,而不包括人力、数据等一切其他成本;
- s1 模型并非只训了一轮,研究人员还做了很多其他的实验和测试。
微调一个模型的目的和成本,与从零开始训练一个模型天差地别,所以如果你真的相信 50 美元可以训练出超过 o1/R1 的模型,那至少至少也要把 Qwen2.5-32B 的训练成本加上。
问题二:真的能超过 o1/R1 吗?
不能。只能通过精心挑选的训练数据,在特定的测试集上,超过 o1-preview,而远远没有超过 o1 正式版或者 DeepSeek R1。
看论文中给出的数据,最后一行就是论文的主要成果 s1 模型:
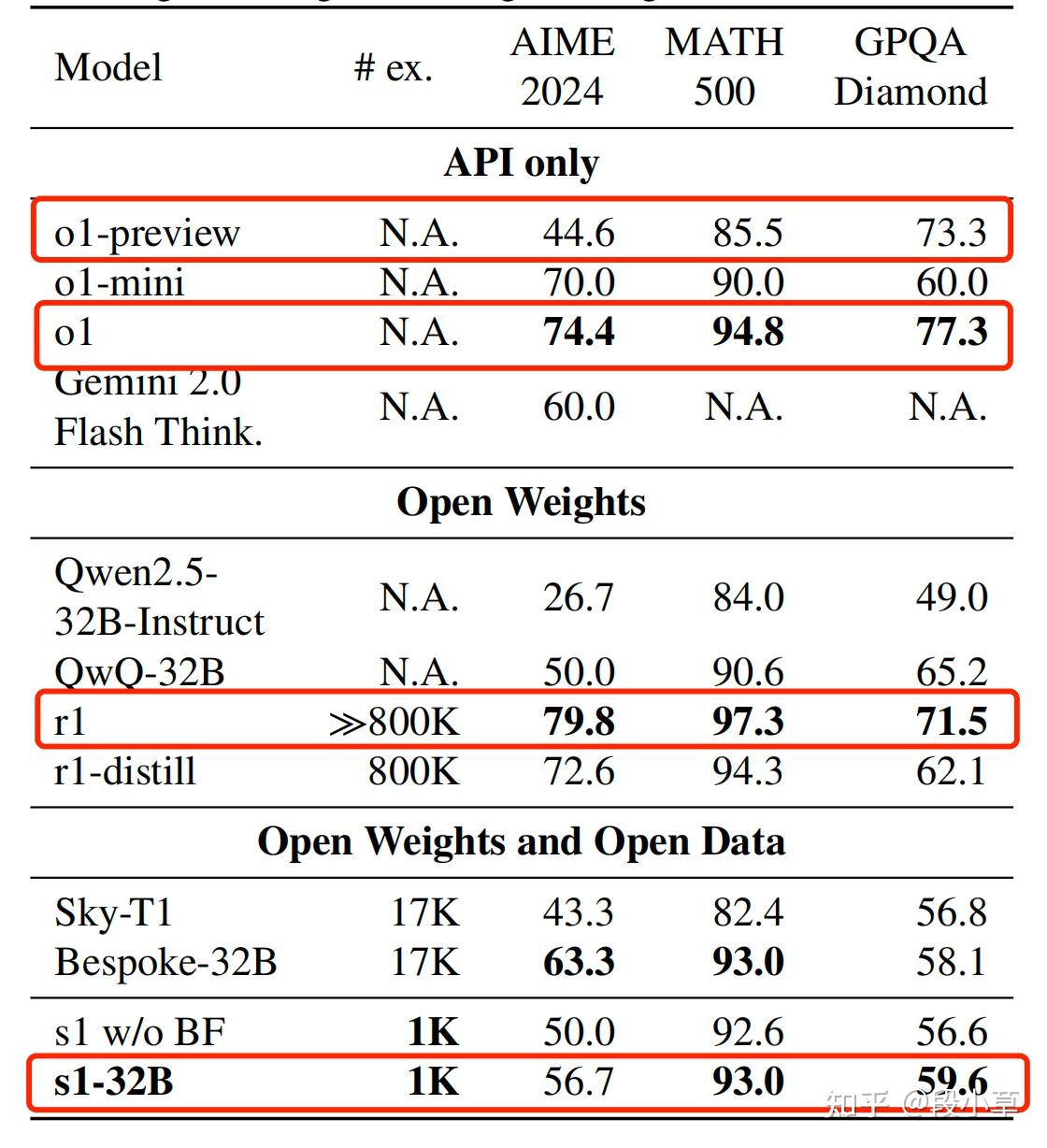
- 在 AIME 2024 上,R1(79.8) > o1(74.4) > s1(56.7) > o1-preview(44.6) > Qwen2.5-32B-Instruct(26.7)
- 在 MATH 500 上,R1(97.3) > o1(94.8) > s1(93.0) > o1-preview(85.5) > Qwen2.5-32B-Instruct(84.0)
- 在 GPQA Diamond 上,o1(77.3) > o1-preview(73.3) > R1(71.5) > s1(59.6) > Qwen2.5-32B-Instruct(49.0)
由此看出,在 AIME 2024 和 MATH 500 两个测试集中,s1 可以超过 o1-preview,但无论在哪个测试集,s1 都没有超过 o1 正式版和 R1,而且可以说差距还很大。
为什么说还需要精心挑选的数据呢?看另一组分数,这是不同用不同数据集微调的分数差异:
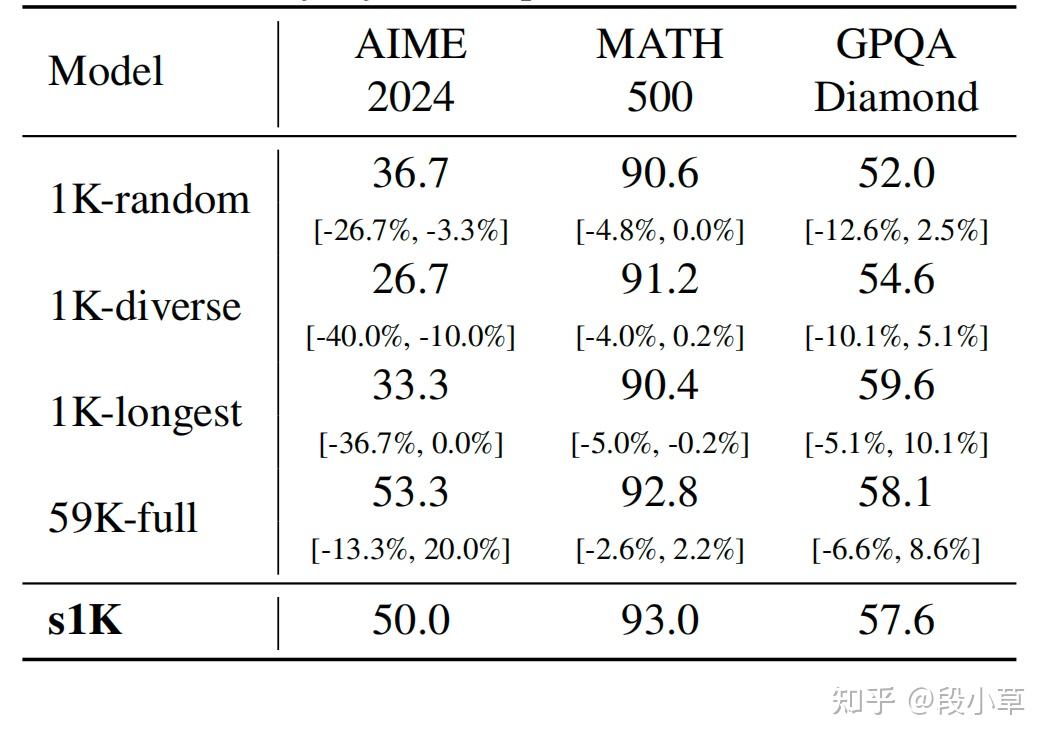
这里的 4 组数据集的区别:
| 数据集名称 | 选择方法 | 选择标准 | 数据量 |
|---|---|---|---|
| 1K-random | 随机选择 | 无特定标准 | 1000 |
| 1K-diverse | 最大化多样性 | 仅考虑多样性 | 1000 |
| 1K-longest | 选择最长的推理链 | 仅考虑难度 | 1000 |
| s1K | 综合考虑质量、难度和多样性 | 质量、难度、多样性 | 1000 |
| 59K-full | 使用全部数据 | 无筛选 | 59029 |
问题三:训练数据真的是「蒸馏」 Gemini 吗?
团队先收集了 59k 问题,然后从中筛选出了最终的 1k 问题。将这 1k 问题提交到 Gemini 2.0 Flash Thinking 中生成思维链和答案,以此构建数据集去微调开源的 Qwen 模型。

尽管我认为,这种做法严格来说不叫蒸馏,而是拿 Gemini 生成数据并对 Qwen 做 SFT(有监督微调),但作者们自己在论文里写了这就是「蒸馏」。
那我只能说,现在「蒸馏」的概念显然已经被扩大化了。这种行为是否属于「蒸馏」,取决于你对「蒸馏」的定义,我没办法给出标准答案。
UPDATE 一下:DeepSeek R1 论文[1]里「蒸馏」Qwen 和 Llama 模型时同样是只用了 SFT 和 R1 的 800K 数据,跟 s1 论文做法一样。,现在只要用 A 模型输出数据 SFT 微调/训练 B 模型就都被叫蒸馏了。
问题四:虽然没超过 o1/R1,但确实能超过 o1-preview,同时微调后也的确比 Qwen2.5-32B-Instruct 进步显著,怎么做到的?
一是微调用的训练数据起到了一定作用;二是强制让模型延长思考时间(test time scaling),具体做法叫做「Budget Forcing」预算强制,也就是强制限制模型使用最大或最小 tokens 进行推理,以此控制模型的思考长度。
为了尽可能延长模型的思考,他们将模型的思考放在<think></think>标签内,当<think>结束后,以 final answer 给出答案,同时,当 LLM 即将停止思考时,会强制输出 Wait 来迫使模型继续思考,通过这样的方式,模型会进入反思,并可能会发现自己的错误。
推理时插入的「Wait」,也许会像当初的 Step by Step 一样,成为一个魔法 token。这或许就是古人「三思而后行」的哲学吧!
所以:s1 和 o1/R1 这种推理模型有本质上的区别,o1/R1 是通过强化学习 RL 训练出的,而 s1 则是通过 SFT 在已有模型基础上微调出来并强行拉长思考的。
另外还有个小问题,就是 s1 的分数提升如果来自微调(SFT) + 强制延长思考(BF),那么这两者究竟哪个更有效,论文中并没有充分体现。在测试成绩中,的确有 s1 w/o BF 的成绩(Qwen2.5-32B SFT 后,不特意延长思考的成绩),但没有 Qwen2.5-32B 自身不微调,直接 BF 延长思考的成绩。如果补充了这个测试,结论也许会更严谨更有说服力。否则按现在的数据,大家会感觉成绩的提升更多来自于高质量数据的微调,再做 BF 似乎也没多大提升。
论文作者对此的回应是:
在基础模型(Qwen2.5-32B)上强制延长思考(Budget Forcing)比较困难,原因如下:
- 基础模型没有专门的思考部分,需要进行提示工程prompt engineering:基础模型本身缺少专门的思考环节,需要通过精心设计的提示来引导模型进行思考。
- 生成的连贯推理(CoT)较短:基准模型的推理链条通常比较简短,可能无法充分展开复杂的思考过程。
- 推理性能较差:推理性能越接近 0,进行 BF 优化的难度就越大。模型的推理能力较弱时,优化推理过程(如 BF)会变得更加困难。