AI 设计Agent-Lovart
官方 Sloga:The world’s first design agent for all design purposes
世界上第一个设计Agent(智能体),适用于所有设计用途
主要特性:
- 通过自然语言对话,Agent 拆解用户需求。
- 生成任务计划,调用专业知识库或素材参考。
- 最后调用顶级图像生成模型如GPT、Flux生成图片。 甚至会用一些专业Lora,解决更垂直的风格设计需求。
这款产品,并没有被 AI 对话产品形态束缚住。 如点图片后出的各个图片编辑功能,Tab对话修改。
我的例子
生成一套基于中国古代知名戏曲片段的塔罗牌设计。
内容要求
场景选取: 从中国古代知名戏曲片段中提取具代表性的场景画面
场景而非人物像: 画面需表现完整戏剧场景,而非单个人物肖像
服饰真实性: 画面中人物必须穿着对应戏曲的正确服饰
视觉风格呈现以下风格特点:
融合巴洛克戏剧性与抽象流动感,整体呈现黑暗、扭曲、诡异的视觉氛围
运用强烈的阴影对比与复杂细腻的烟雾纹理,营造极具张力与表现力的构图
这里是它给我出的一组图

视频(左边):生成内容支持二次手工编辑,还将相关的编辑功能放在了一起,能够支持添加文字、形状、路径,这样在一个工具里就能完成最终的内容了
图片(右边):这是一个盲盒里的公仔,我想制作一个闪卡放在盲盒中,这一招是太极中的云手,这个公仔的名字是臣走兔;为我设计一个适配这个风格的

现阶段还是处于内测阶段,我放几个邀请码供大家体验
邀请码(一行一个):
JFMhEyJ
MCWWq4u
PnQfLME
QpYD7qh
Google Veo 3 发布-视频和声音一起生成
- Veo 3具备强大的文本和图像转视频能力,首次实现了视频与音频的同步生成,包括口型同步。
- Veo 3能够生成逼真的视频,例如战场士兵、车展视频和ASMR视频,视觉和音频效果都达到了极高的逼真度。
- Veo 3在生成复杂动作和场景转换时存在局限性,例如体操类视频和篮球视频的生成效果不佳。
视频1来自官方 视频2来自网络(Veo3 已经可以用来做游戏美术的原型参考)
视频3实测 (我想要一个像素风人物在沙土满天飞的沙漠中前行的视频,看到一只九色鹿说 看 快看;场景需要敦煌那样的色彩)
Rick Rubin《The Timeless Art of Vibe Coding》与《道德经》的哲学共鸣
每一章节都有对应;
“道”与“代码”的哲学类比
Rick Rubin 在《The Timeless Art of Vibe Coding》中将《道德经》的“道”与编程中的“代码”巧妙类比,提出真正的代码之美超越具体形式,指向无形的真理。文章引用《道德经》开篇:“道可道,非常道。名可名,非常名。”并改编为:“The code that can be named is not the eternal code. The function that can be defined is not the limitless function.”
无名之妙:完美代码的本质是“无名”,即超越具体功能、类或脚本的抽象理念。有名之形:具体代码只是“道”的表现形式,程序员应追求背后永恒的和谐与自然。


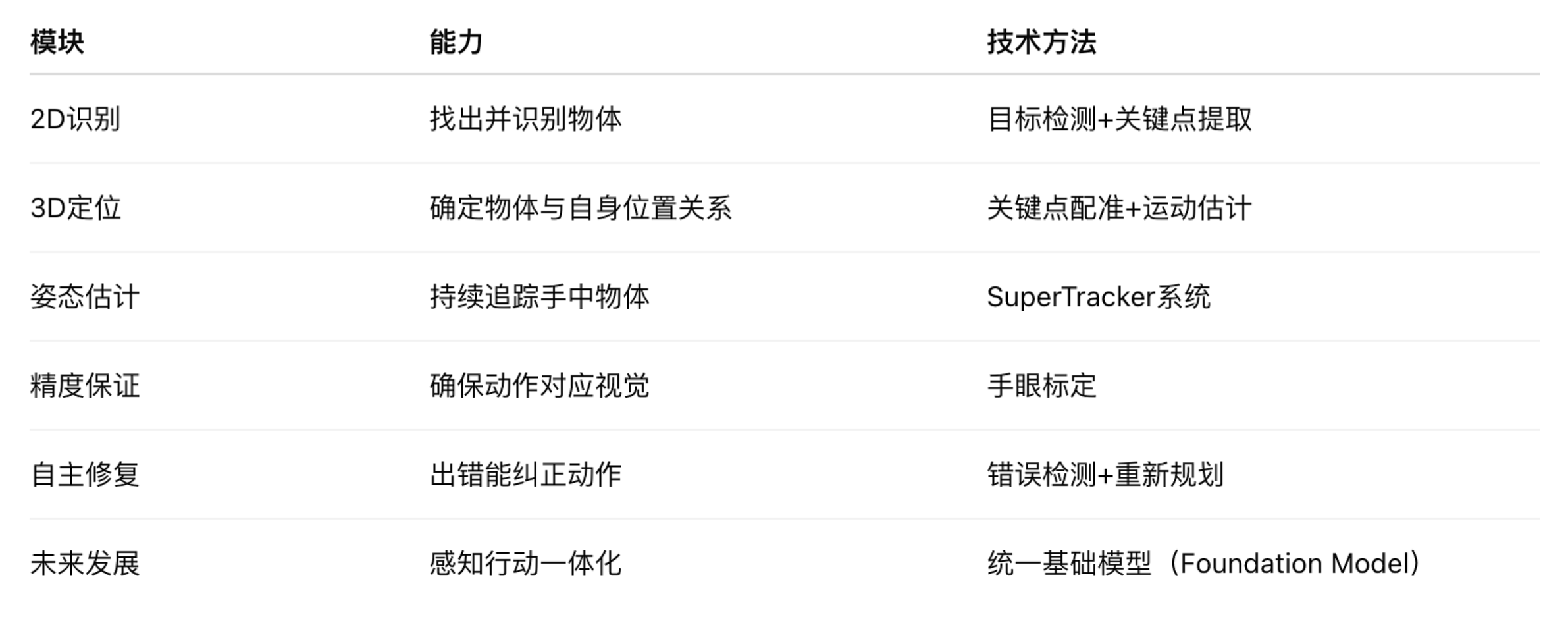
波士顿动力公司分享了其 Atlas 机器人的感知系统和视觉能力构建方法
- Atlas现在能够有效处理遮挡和不确定性。精准的校准确保了精准的手眼协调,从而实现可靠的操控。
- 波士顿动力公司的人工智能团队解释了他们如何让 Atlas 人形机器人感知世界并与世界互动。
- 这是一个融合了图像识别、三维几何理解、 实时控制、错误恢复、与任务规划的复杂感知-决策系统。

新一代多模态图像生成与编辑模型:FLUX.1 Kontext
可以实现GPT 4o图像生成和编辑能力
主要特点:
- 角色一致性:可在多个场景中保持人物或元素的一致性
- 局部编辑:只编辑图像的特定部分,不影响其他区域
- 风格参考:可在指定风格下生成新场景
- 交互速度快:推理速度高达当前主流模型的 8 倍
下面两个图是我让他拿手办效果图做的手绘稿子


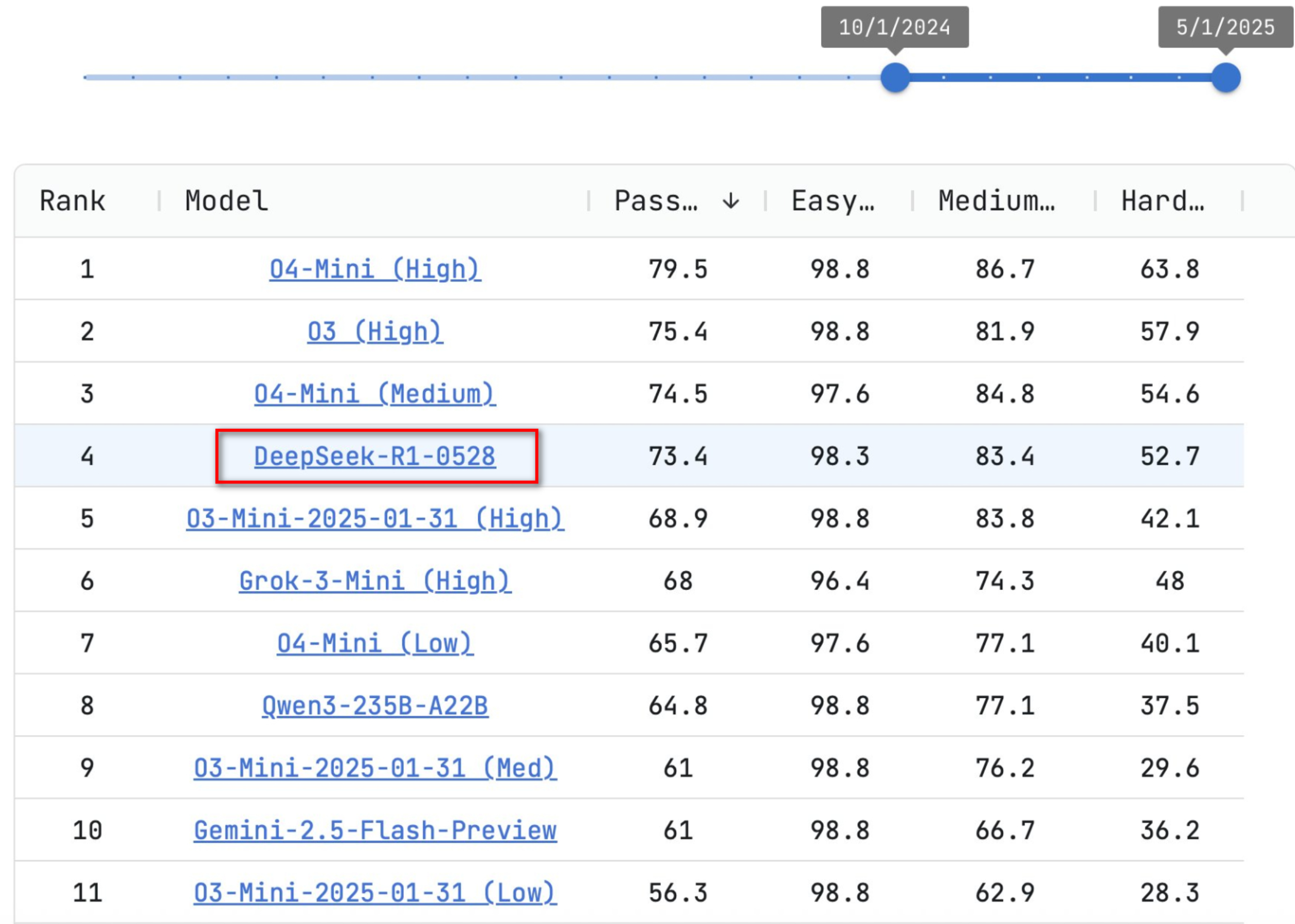
05-29 DeepSeek发布新版R1模型DeepSeek-R1-0528,并公开模型及权重
- DeepSeek-R1-0528在数学、编程和逻辑推理方面表现优于前版本,且减少了“幻觉”现象。
- DeepSeek-R1-0528参数量高达6850亿,开源但大多数人只能围观,如果「满血版」不进行蒸馏,是肯定无法在消费级硬件上本地运行的。
- 新版R1在LiveCodeBench上的表现接近OpenAI o3-high。新R1能够解决一些之前被顶级模型,如o3、Gemini 2.5 pro、Claude 4等难住的难题。
- DeepSeek R1采用MIT许可证,可用于商业用途。
- 实测DeepSeek-R1-0528代码能力大幅提升
OpenAI 将企业或者你的内部知识与 ChatGPT 深度融合
- Connectors(连接器):将企业内部知识源(如GitHub、Dropbox、SharePoint等)可以连接至 ChatGPT,实现私域知识的智能检索与分析。
- Record Mode(记录模式):ChatGPT可以自动记录、转录、摘要你会议内容。 通过全新的连接器系统,用户可以让 ChatGPT 接入如 Outlook、Google Drive、Gmail 等关键工具,并在权限范围内获取实时上下文信息。对于企业级用户,还支持接入 SharePoint、Dropbox、Box 等服务。
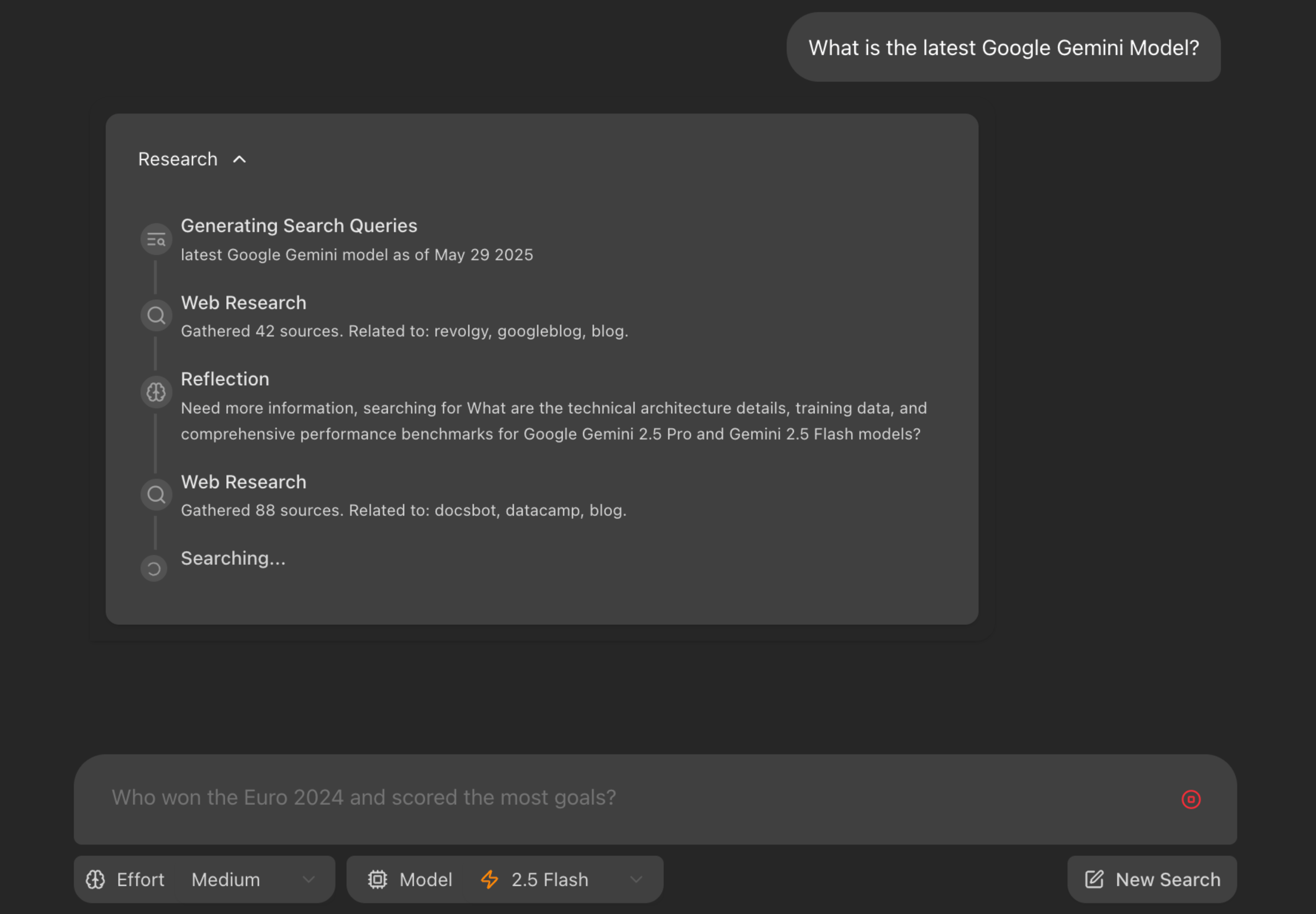
谷歌开源了一套Deep Research应用
使用 React 前端和 LangGraph 驱动的后端代理的全栈应用程序。该代理旨在通过动态生成搜索词、使用 Google 搜索进行网页查询、反思搜索结果以识别知识缺口,并不断优化搜索,直到能够提供包含引文的、支持充分的答案,从而对用户查询进行全面的研究。此应用程序是使用 LangGraph 和 Google Gemini 模型构建研究增强型对话式 AI 的示例。