这是第九期周刊,每
周五发布!
Meta刚刚开源了首个行为基础模型:Meta Motivo
用于控制虚拟人形智能体的行为,可以让它执行复杂的全身控制任务,比如动作跟踪、目标姿势达成等
无需额外训练就能适应环境变化。它的灵活性和自适应能力比较好,为完全具身化的智能体带来了可能性,用它像开发游戏NPC、角色动画制作更方便了
github:https://x.com/aigclink/status/1867735435843448984
Gemini案例
让上古卷轴5的NPC和Gemini进行实时对话,来推进剧情
Refly 是基于「自由画布」理念打造的 AI Native 创作工具
在自由画布上进行多主题&多线程对话功能,让您借助 AI 自由发散思维,梳理创作思路
集成写作素材与 AI 知识库,打造强大的大脑系统
采用类似 Cursor 和 NotebookLM 的上下文记忆功能,实现精准定位修改
内置类 Perplexity 的 AI 全网搜索与知识库检索,突破信息获取瓶颈
融合 Notion 风格的 AI 编辑器与 ChatGPT Canvas 式文档处理体验,让创作更加行云流水
(当前还在内测中)
Google 的新工具:Whisk,可以简单的用图片组合生成新的图片
用户可以输入三类图片:
- 主题图片(subject)
- 场景图片(scene)
- 风格图片(style)
就可以基于输入生成新的风格突破 背后的技术技术原理:
- 后端使用Gemini模型自动为输入的图片生成详细描述
- 然后将这些描述输入到Google最新的图像生成模型Imagen 3中
- 系统会提取图片的关键特征,而不是完全复制
主要用途:
- 快速视觉创意探索
- 可以创作数字玩偶、珐琅徽章或贴纸等
- 适合进行快速创意迭代,而不是精确的图像编辑
目前该服务仅在美国地区开放使用,可以通过http://labs.google/whisk 访问。
(试了一下效果还可以)
谷歌发布 Veo 2 视频模型
-
支持生成高达 4K 分辨率视频,可以延长到几分钟
-
非常详细的画面细节表现 - 足够真实的物理交互
-
可以完成非常复杂的动作
案例:低角度拍摄捕捉到一群粉色火烈鸟在郁郁葱葱、宁静的泻湖中优雅地涉水。它们鲜亮的粉红色羽毛与周围翠绿的植被和晶莹剔透的碧绿海水形成了美丽的对比。阳光在水面上闪闪发光,在火烈鸟的羽毛上产生闪烁的倒影。当它们穿过浅水时,它们优雅而弯曲的脖子被淹没,它们的动作产生轻柔的涟漪,蔓延到整个泻湖。构图强调场景的宁静和自然之美,突出生态系统的微妙平衡和这些宏伟鸟类与生俱来的优雅。清晨柔和、漫射的光线使整个场景沐浴在温暖、空灵的光芒中。
几大主流AI视频模型横向评测
Google Veo 2 真实世界物理规律模拟测试
谷歌 Veo 2 这个水墨动画效果很好
Google同时发布了改进版Imagen 3
Midjourney的数据集还是审美好一点,但是他的指令跟随性还是太差了;细节和提示词理解谷歌好点
[clip对提示词的理解能力太差了,谷歌估计把clip换了]
看看和 Midjourney 的对比
一只浅米色的长毛猫在街头旅行时自拍。她穿着连帽衫,戴着金项链,站在涂鸦墙背景前。嘻哈风格

白色背景下,一朵模糊的心形红花在运动,这是使用柯达 Portra 800 胶片以柔和的光线和低反差拍摄的,具有彼得-林德伯格的风格。

自上而下俯瞰,一朵法桐花轻轻地漂浮在平静清澈的水面上,娇嫩的白色和黄色花瓣被阳光柔和地照亮。花朵周围泛起微微涟漪,营造出宁静祥和的氛围。水面反射出柔和的热带绿意,背景呈现出美丽的自然虚化效果。拍摄于巴厘岛,逼真而宁静

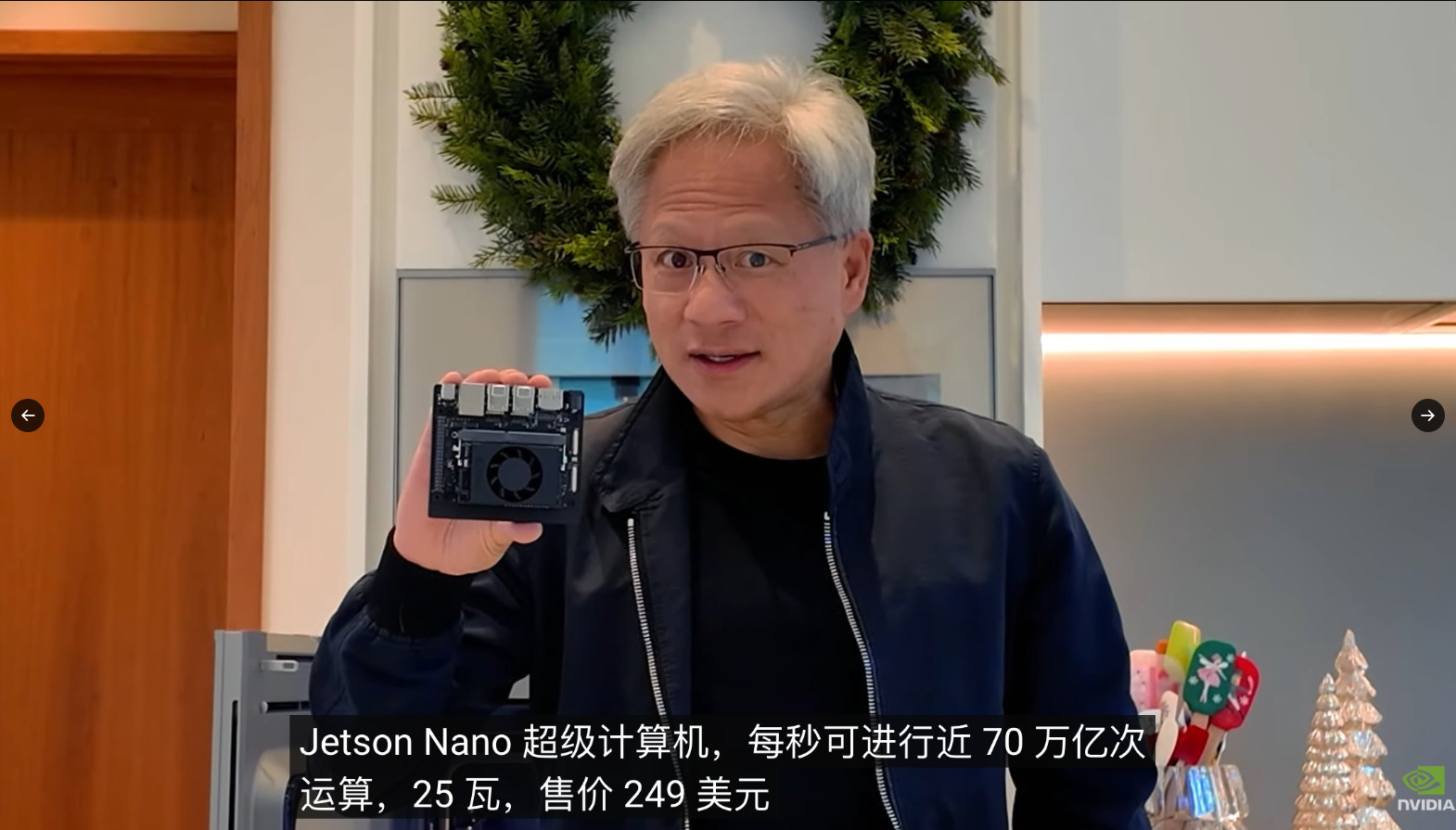
NVIDIA Jetson Orin™ Nano Super:世界上经济实惠的 AI 电脑
为开发人员、学生和构建人员提供了最经济实惠、最容易获得的平台,并得到了英伟达™(NVIDIA®)人工智能软件和广泛的人工智能软件生态系统的支持。
Genesis Project : 这是一款生成式物理引擎 ,支持生成4D动态真实的物理世界 !
纯Python开发,速度比现有GPU加速引擎(如Isaac Gym、MJX)快10-80倍,模拟速度比实时快约43万倍。
在单张RTX4090上仅需26秒 完成可转移到真实世界的机器人运动策略训练!
经过24个月、由20多个研究实验室的大规模合作研发!
目标 :
构建一个统一的生成式物理世界模拟框架,自动生成各种环境、机器人任务、奖励函数、交互式3D场景等,助力机器人与物理AI领域的全面发展。
完全开源 ,代码地址:https://github.com/Genesis-Embodied-AI/Genesis
项目地址: http://genesis-embodied-ai.github.io
(虽然开源但是使用教程没有,并且window运行不了渲染部分,代码里调用opengl的方式不支持windows)
ElevenLabs 全新语音生成模型:Flash
可以在75ms内生成高质量的媲美人类的语音
Flash v2 仅支持英语,而升级版 Flash v2.5 支持 32 种语言。
尽管其情感深度稍逊于内部的 Turbo 系列模型,但与竞争对手相比,Flash 的语音质量仍然领先。
该模型的使用成本为每 2 个字符消耗 1 点积分,用户可根据自身需求选择最合适的模型版本
支持通过 API 或平台直接使用
白板/绘图工具 tldraw 新产品:tldraw computer
不叫工作流、agent、程序…而是用更拟人、更卡通当然也对普通用户而言更形象的“computer”
本质是基于 tldraw 无限白板的 AI 工作流,用户可以自行设计流程(支持分支、循环等程序逻辑),控制 AI 得到结果
这是继用 Minecraft 搭建 CPU 以来最有趣的“计算机”产品概念
AI 功能的合作方是 Google Gemini
大大降低使用门槛,让ai、多模态这两个真正的离普通人近了很多
OpenAI 连续 12 天 AI 发布会:第七天-第十一天
第七天:发布会主要是 ChatGPT 的一个新功能 Projects(项目)
通过项目可以你可以上传文件、设置自定义指令,类似于 GPT,但是不同于 GPT 的主要是你可以在一个Project中将所有对话组织在一起,还可以把现有会话加入进去。
ChatGPT 的 projects 现在支持选择模型了,可以选择包括 o1 在内的模型
第八天: ChatGPT搜索功能的三大更新
首先是提升了搜索性能,让它在移动端更快、更好用,还加入了地图体验;
其次是将搜索功能整合到了语音模式中,让用户可以通过语音对话获取实时网络信息;
最重要的是,搜索功能现在向全球所有登录用户免费开放。
在演示环节,产品团队展示了如何用ChatGPT搜索周末活动、寻找餐厅、规划假期等实用场景,特别展示了它能够保持对话上下文、理解用户意图的能力,比如在餐厅搜索中自然地加入"户外露台和加热器"这样的新要求。
整场演示生动地展现了ChatGPT如何让搜索变得更加智能和对话化。
ChatGPT Search 中文搜索质量低下难题的解决方案:一劳永逸,干净利落解决中文资料质量问题
中文搜索时,因为百度百科等资料的原始质量低下,以讹传讹,所以,GPT 的回答是错误的;
使用英文提问,ChatGPT 默认使用英文搜索,Wikipedia 等资料中的信息是对的,所以 ChatGPT 的回答是正确的;
解决中文资料信息质量问题的办法。还是中文提问,结尾加一句“search in english”,问题解决。干净利落,一劳永逸~
第九天:主要是针对开发者的,有多个API相关更新
首先是广受期待的o1 API正式版本,这个版本不仅速度更快、成本更低,还加入了视觉识别、函数调用等新功能,让开发者能够更轻松地构建各类应用。特别值得一提的是,它比之前的版本节省了60%的计算资源,这意味着开发者可以用更低的成本获得更好的性能。
在语音交互方面,OpenAI通过引入WebRTC支持,极大简化了实时语音应用的开发流程。现在,开发者只需要12行代码就能构建基础的语音交互功能。同时,OpenAI 大幅下调了相关服务的价格,其中GPT-4o的音频处理费用降低了60%,这无疑会让更多开发者有机会尝试语音应用开发。
另一个引人注目的更新是"偏好微调"功能。这项技术允许开发者根据用户偏好来定制AI模型的回答风格和内容。比如,一家金融科技公司使用这个功能后,他们的AI助手准确率提升了5个百分点以上。这对于需要个性化AI服务的企业来说是个好消息。
其他还有:新推出了Go和Java版本的开发工具包,简化了API密钥的申请流程,并在YouTube上分享了详细的开发指南
第十天:主要介绍了通过电话和 WhatsApp 使用 ChatGPT 的新功能。
ChatGPT电话服务,1-800-24284-78,不能说这个功能没用,但也不能说它很有用,只能说很鸡肋。对于特殊场景来说,网络信号不好,又需要翻译的情况下,这是个有用的功能。
目的是向下兼容,降低使用门槛
第 十一天:展示了 ChatGPT 桌面应用如何与各类应用无缝协作,让工作更高效。
- ChatGPT 桌面应用全新升级,支持与多种应用程序协同工作
- 实时演示与 Warp 终端、Xcode IDE 的智能协作
- 发布对 Notion、Apple Notes、Quip 等写作工具的支持
- 推出全新的高级语音交互模式
- 展示搜索辅助功能,确保输出信息准确性
核心功能演示
- 终端协作:通过 ChatGPT 分析 Git 提交数据并生成可视化图表
- IDE 支持:在 Xcode 中实现代码自动补全和功能添加
- 文档写作:结合 Notion 完成旧金山历史徒步旅行规划
- 语音交互:通过圣诞老人角色展示智能语音助手功能
可用性信息
- Mac 版本现已正式发布所有演示功能
- Windows 版本即将推出
- 用户只需更新到最新版本即可使用全部新功能
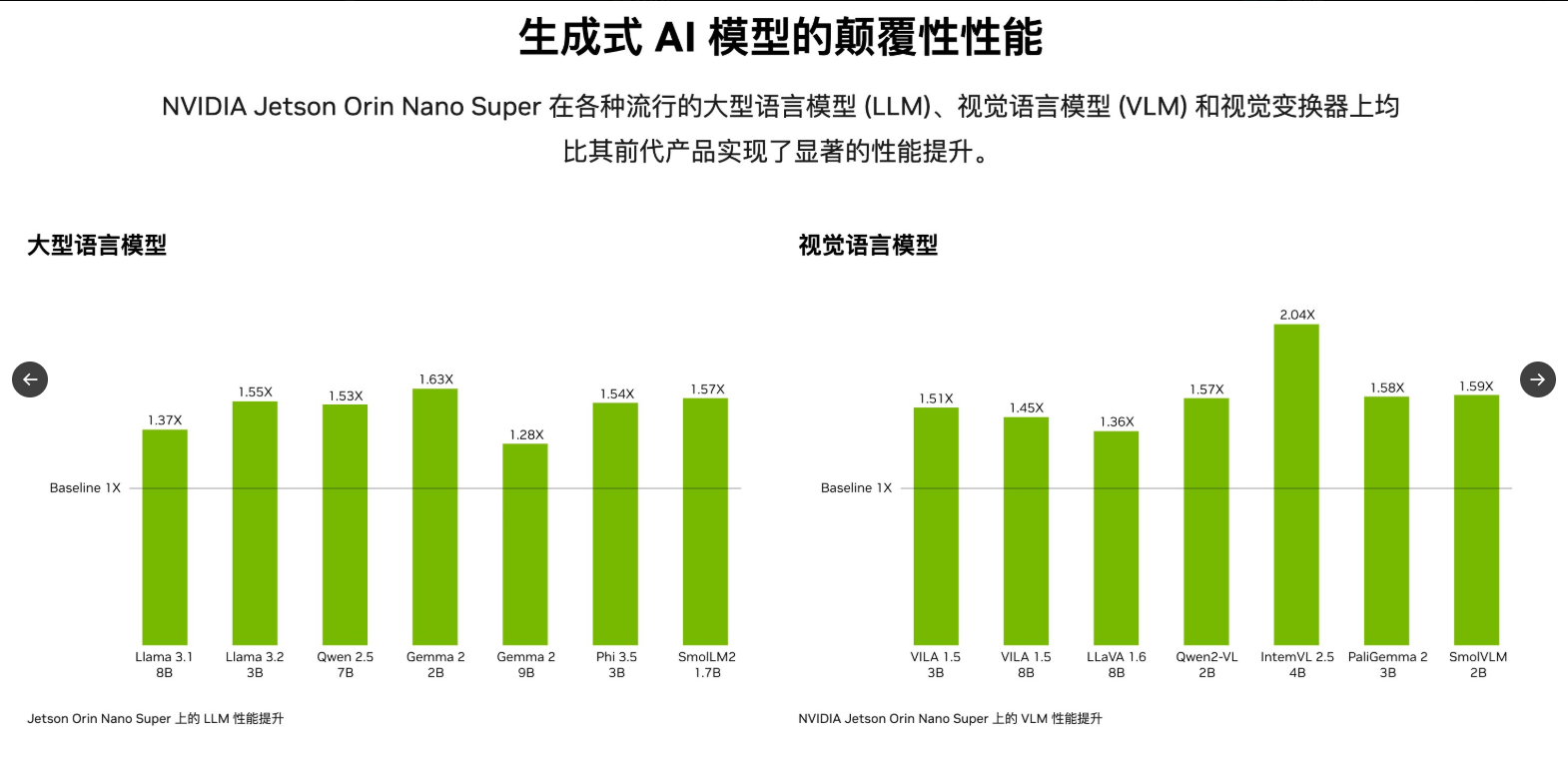
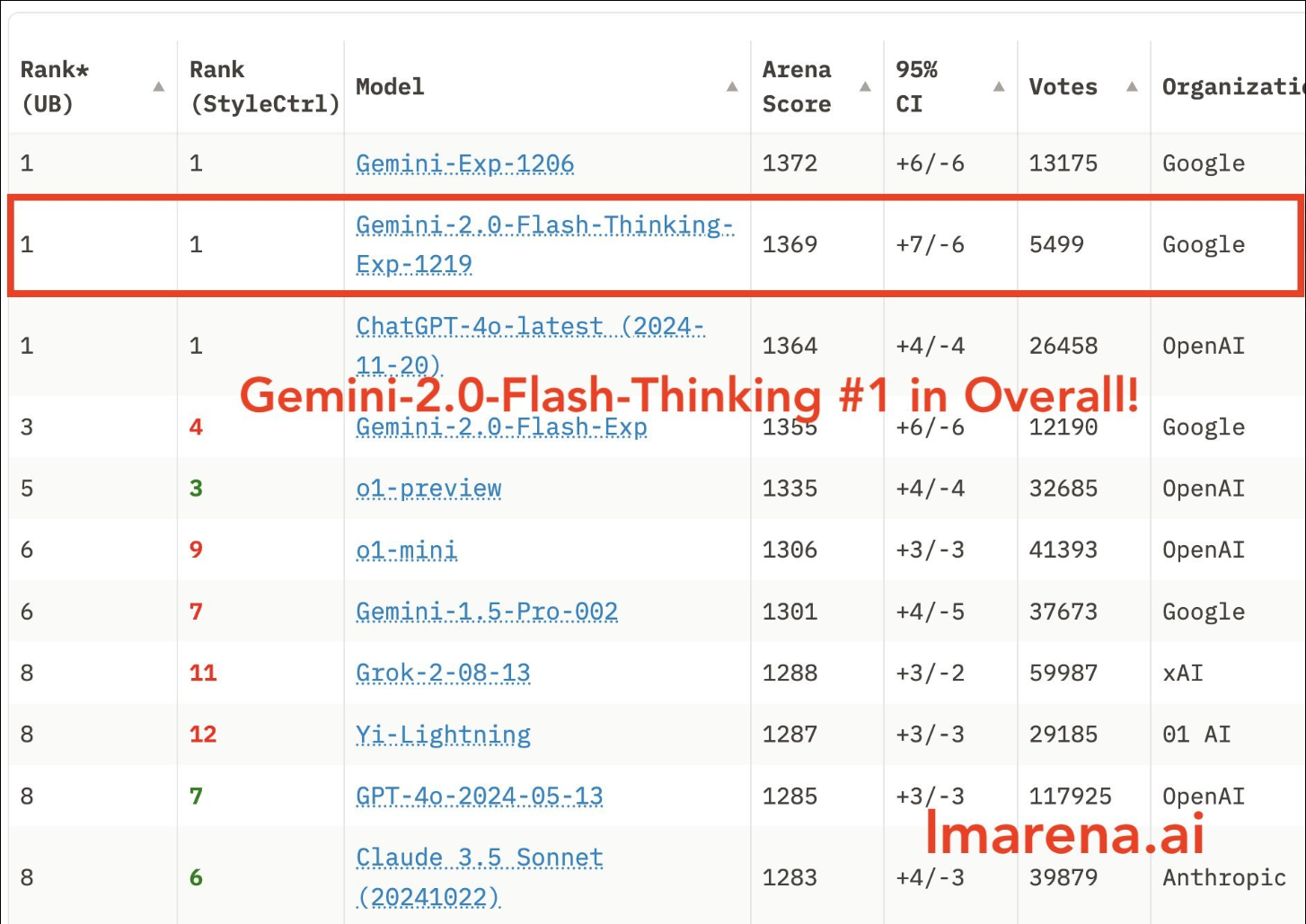
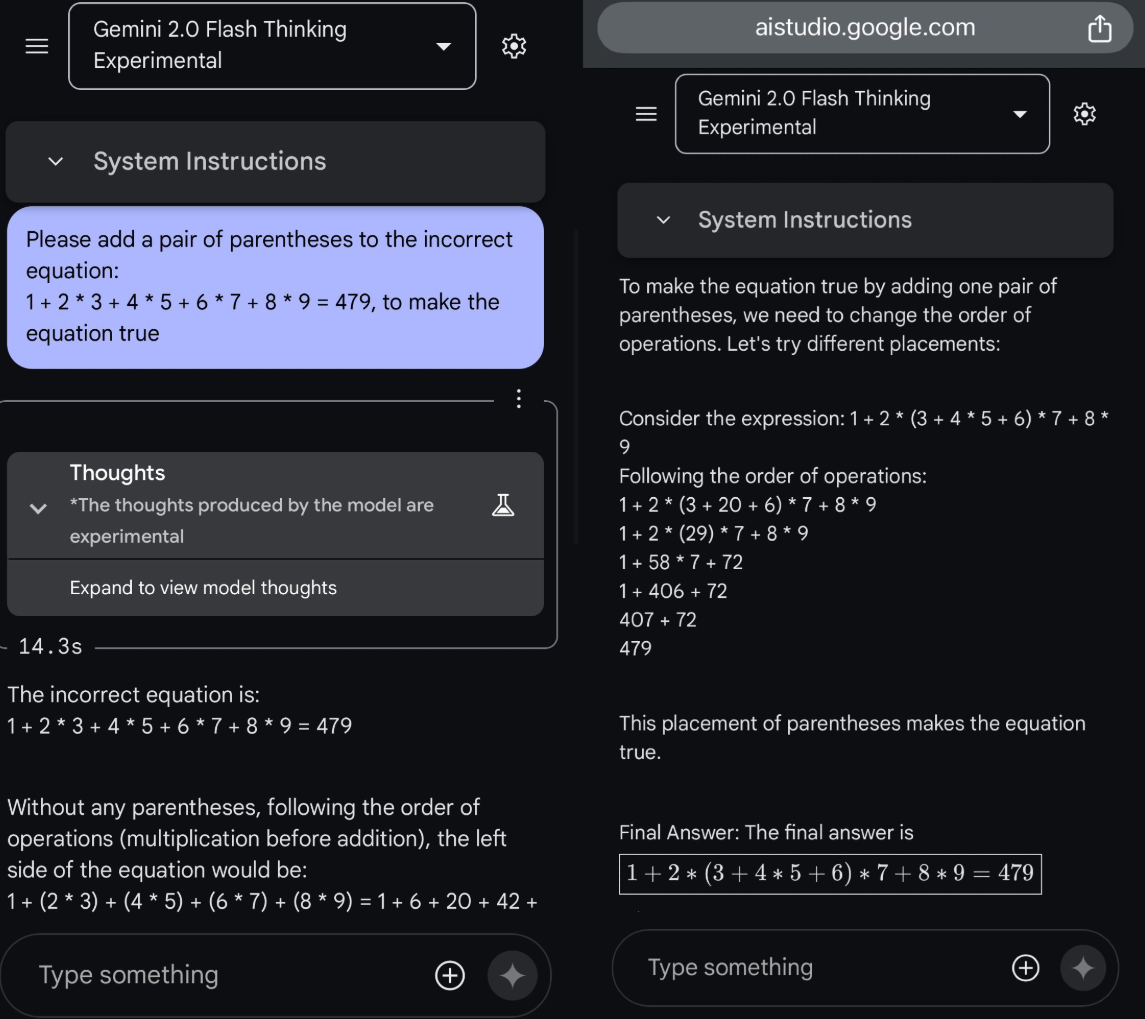
Google 悄悄推出了 Gemini 2.0 flash 的 Thinking 模型
专门为推理优化,类似与 OpenAI o1,但不同的是 Thinking 给出了完整的思考步骤和自己的选择,而且速度极快!
直接在 LMArena 所有类别拿到第一,而且比 O1 快 5 倍!
现在可以直接在 AI Studio 免费使用,推理过程公开
Unitree 宇树科技开源了其机器人训练的所有源代码
包括了 强化学习(RL)训练代码、从模拟到模拟(Sim-to-Sim) 和 从模拟到现实(Sim-to-Real) 的源代码。
该项目可以帮助开发者或研究人员在虚拟环境中模拟和训练机器人,然后把训练结果转移到机器人上。
这是宇树科技Unitree H1、H1-2 和 G1 机器人已经验证过的技术。
github:https://github.com/unitreerobotics/unitree_rl_gym
字节跳动发布豆包视觉推理模型
模型可以识别和理解图像中的丰富信息,包括图像知识、动作情绪、位置状态、文化背景和文字信息。

豆包视觉理解模型不仅能够识别图像中的物体、人物、景物
以及它们之间的关系
模型还可以通过对图片的分析
识别出图片中具体物体、动作、情绪、背景等信息
