这是第六期周刊,每
周五发布!
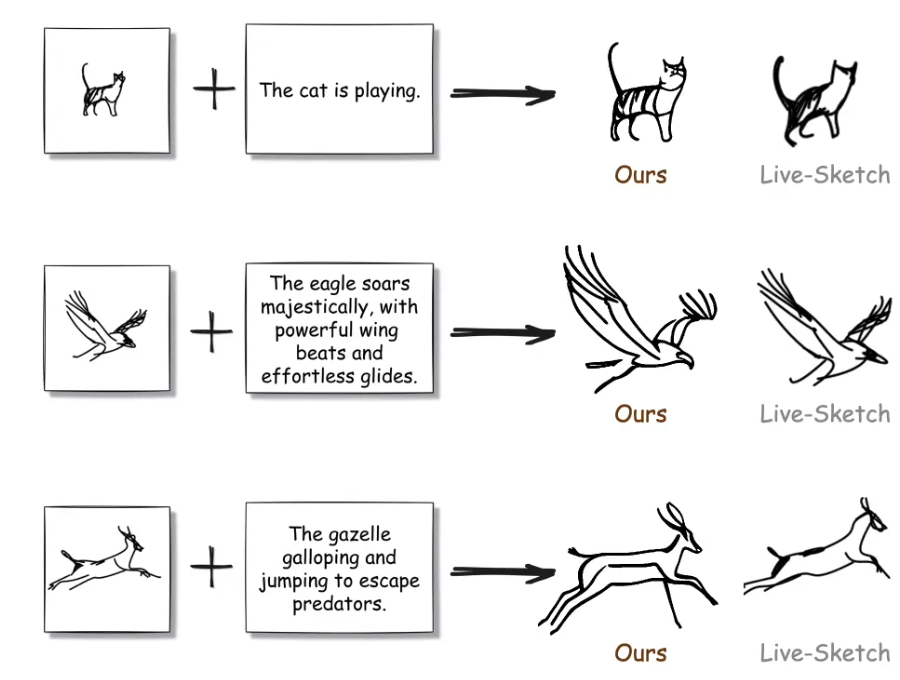
支付宝发布 EchoMimicV2:从数字脸升级到数字人
支持图片 + 音频生成半身动画视频,包含头部、手势和上半身动作。
动作与声音匹配更精准,语气与节奏可反映在手势和表情变化中。只需输入一张图片、一段手势视频和一段音频,即可生成数字人。支持中英文驱动,画面稳定性非常好。
FlipSketch:开源草图动画生成技术
FlipSketch 是一个开源技术,旨在将草图转换为草图风格的动画。用户只需输入一个草图和一段文本描述,即可生成动画。虽然从演示来看,动画效果差点意思,但好在它是开源的。
Runway 发布 Frames:强大的图像生成与风格控制模型
Frames 是 Runway 最新发布的图像生成模型,最大特点是风格控制能力,能够批量生成风格统一的图片素材,可以拿来做故事绘本、视频素材等。这个新模型还没有完全开放,正通过 Gen-3 Alpha 和 Runway API 向用户开放,可以关注下。

Adobe 发布 MultiFoley:创新视频配音技术
MultiFoley 是 Adobe 发布的一项专为视频配音的技术,支持通过文本、音频和视频进行多模态引导。
用户可以利用 MultiFoley 为无声视频添加声音,甚至创造出奇特的效果,例如让猫咪发出狮子的咆哮声。该模型还允许用户从音效库中选择参考音频或部分视频进行条件控制,从演示来看,效果非常出色。不过,目前仅提供了论文,似乎不会开源。
Luma 推出的全新 Dream Machine
可以帮助你把脑子里的想法变成现实 无需专业提示工程,通过自然交互就能你脑子里想象的画面出来。 通过 “角色参考” 功能,用户可以将单一图片转化为动态角色,并在多种场景中重塑角色形象。
还有一些工具和功能:
- “镜头运动”和“起始与结束帧”功能,可轻松导演和定制完美视频效果。 提供循环功能,让视频可以平滑衔接并无限循环。
- 参考和重混任何东西 你可以上传自己的图片、风格,甚至把一张照片和另一个融合变成一个独特的角色,再用它创作更多作品。
- “角色参考”功能可将单一角色转化为独特角色,并在图像和视频中活化。
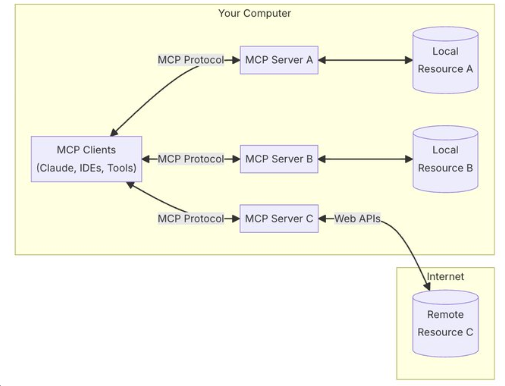
Anthropic 开源了 「模型上下文协议」MCP
可无缝连接本地和远程数据源 MCP 提供了一个通用的标准,任何数据源(比如一个公司的数据库或存储系统)都可以通过这个标准和 AI 进行无缝连接。 MCP 就像一个“万能钥匙”,不需要为每种数据源编写特定的代码。 现在通过 Claude Desktop,简单配置一下 MCP,就能让 Claude 直接连接 GitHub,创建仓库,提交 PR,一键搞定!
MCP 支持在 AI 应用和数据源之间建立双向的、安全的通信通道。 这意味着: 数据源可以安全地共享数据给 AI。 AI 应用也可以把生成的结果反馈给数据源,实现闭环的交互。 这种双向连接保证了数据的隐私性和交互的完整性。
去水印工具
测试了下,果然不是盖的!多厚的水印都能干掉 而且去除的非常干净
当然也有失败的时候 比如如果水印是挡住眼睛,可能有瑕疵 但是绝大部分情况下都很完美
在线体验:https://kaze.ai/toolkit/watermark-removal
官方示例


Claude AI新增功能:允许用户自定义AI回复风格,提升人机互动效率和自然度
-
提供预设样式(简洁、正式、解释性等),满足不同需求。
-
支持自定义样式:上传文本样本或描述需求,让Claude学习用户偏好风格。
-
可管理自定义样式:重命名、预览、删除、编辑及调整顺序。
-
通过案例展示不同模式下的输出效果差异,并演示自定义风格的创建和调试过程。
-
用户可随时切换和调整回复样式。

360发布全新AI搜索产品“纳米”,主打“搜-学-写-创”流程,强调从用户微观需求出发,实现信息再创作。
- 360发布全新AI搜索产品“纳米”,与现有360AI搜索并存。
- “纳米”主打“搜-学-写-创”四个流程,提供多种信息处理和内容创作功能,例如拍照搜索、视频总结、AI口播生成等。
- “纳米”强调信息再创作,用户可基于搜索结果进行二次加工,生成视频脚本、脱口秀等多种内容形式。
- “纳米”已与部分名人达成语音授权合作,例如李雪琴和徐志胜。
- 360的目标是将“纳米”打造成为世界第一的纯AI搜索引擎。
智谱AutoGLM 全新升级,跨APP联动,同时发布全新GLM-PC
可以在手机和电脑上全自动执行任务
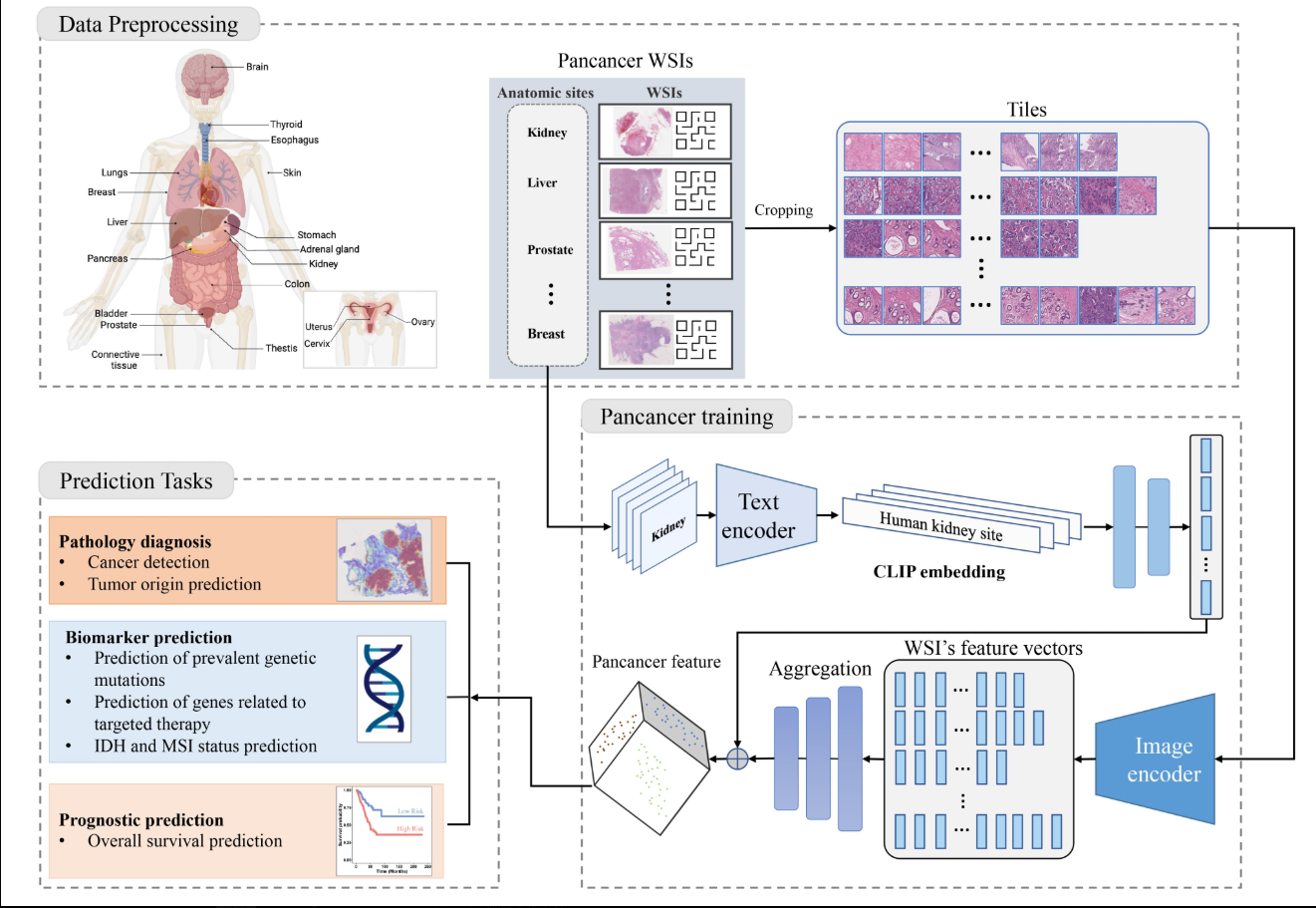
哈佛医学院开源的一个:临床组织病理学影响评估基础模型CHIEF
它是一个通用的病理图像分析AI模型,它解决了现有AI模型在不同医院、不同人群样本间泛化性差的问题,可以适应不同医院/人群的数据
这个通用AI模型可以自动分析病理切片照片,能识别癌细胞、判断癌症部位和类型、预测病情发展 用了60530张全幻灯片图像数据进行训练,覆盖了19个不同解剖部位,采用无监督预训练和弱监督预训练两种方式,预训练使用了44TB的高分辨率病理影像数据集 用了24家医院的19491张图像进行了验证,性能比现有最好的深度学习方法提升最高达36.1% 它可以帮助医生更快更准确的诊断,现已开放,研究者或医院可以直接用
github:https://github.com/hms-dbmi/CHIEF
英伟达的一个3D生成项目:Edify 3D
可在2分钟内生成高质量、可用于生产的3D模型,还可以生成复杂的3D场景 它可以提供精细的几何网格结构、整洁的拓扑布局、规范的UV贴图分布、4K分辨率的纹理贴图,以及完整的基于物理渲染(PBR)材质系统 与其他文本到3D相比,3D形状和纹理优质,在效率和可扩展性方面优秀 支持文本生成3D或图片生成3D。目前它的使用方式还未出
博客:https://research.nvidia.com/labs/dir/edify-3d/
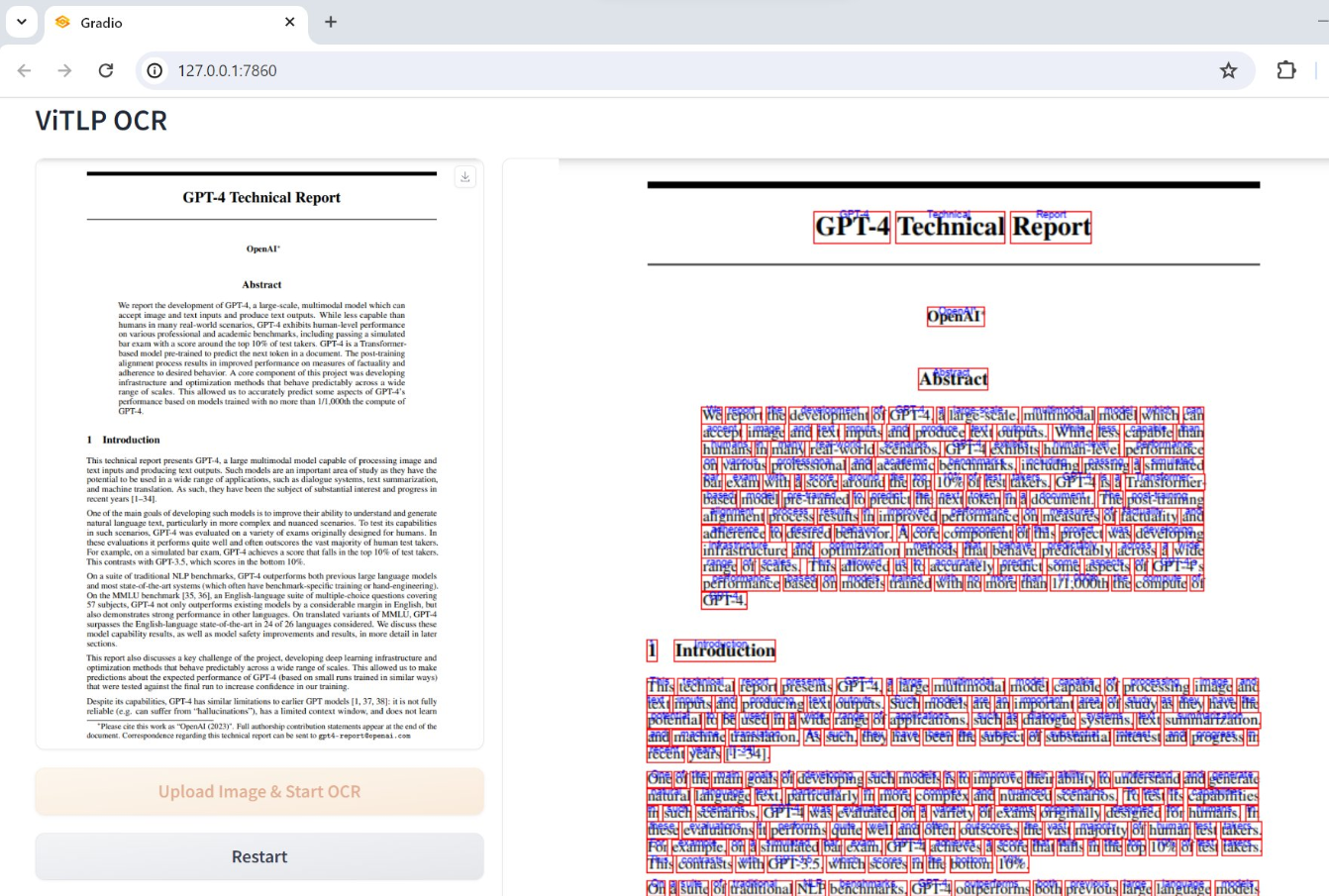
一款基于AI的智能文档处理模型:ViTLP
它可以原生执行OCR文本定位和识别,还可以理解文档的整体布局结构
1、端到端处理,从图像输入直接到结构化输出
2、准确度比较高,在4090上处理一页文档5-10秒
3、文字识别、布局分析、结构理解一体化的,可以保留原始文档的排版结构
4、支持本地部署
github:https://github.com/Veason-silverbullet/ViTLP
手部灵活性靠拢人类:特斯拉 Optimus 机器人新突破,配 22 个自由度
Optimus 工程师米兰・科瓦奇(Milan Kovac)随后发布了演示的详细说明,表示第二代 Optimus 机器人在手腕精细程度上更加灵活,手部有 22 个自由度(DoF),腕部有 3 个,能够模仿人类肌腱结构,更自然流畅地完成更复杂的任务。