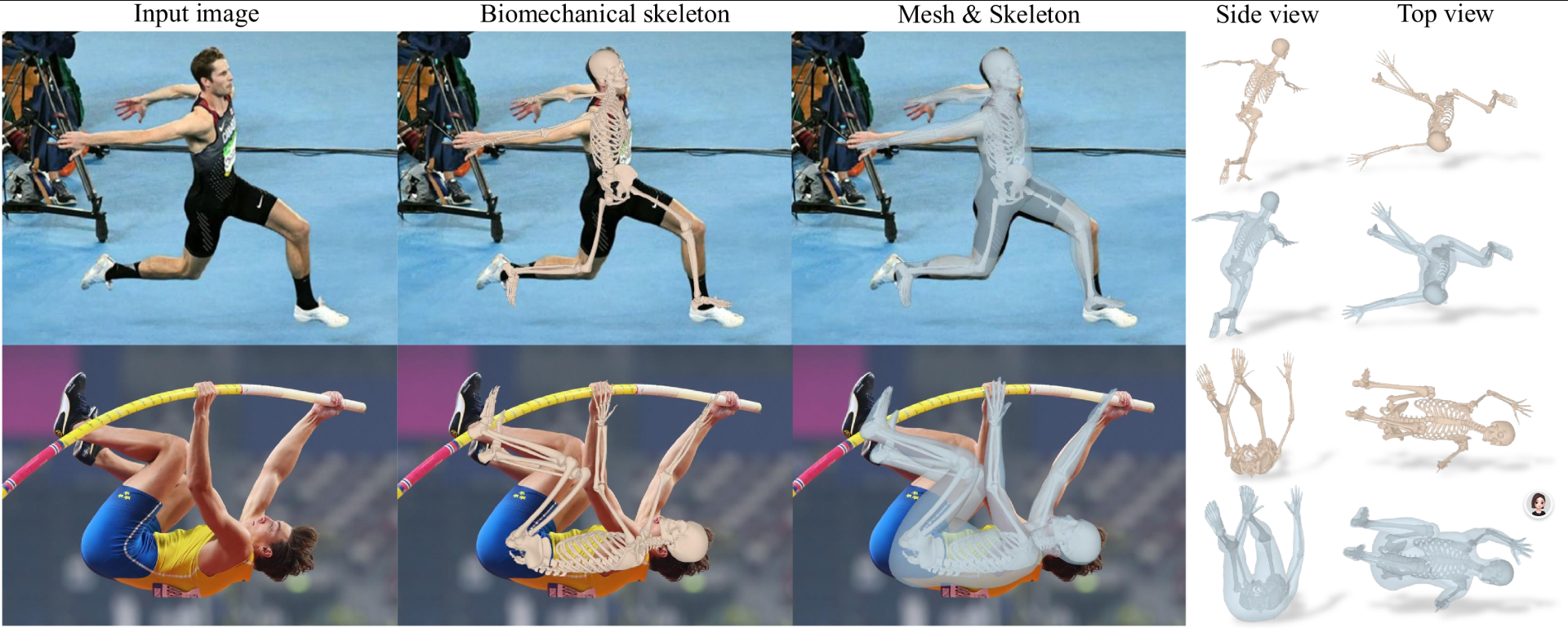
一款从单张图像重建人体3D骨骼和网格模型的系统:HSMR
可以把一张普通人物照片转换成具有生物力学准确骨骼结构的3D人体模型
HSMR能从单张图像中端到端重建生物力学精确骨骼参数,也提出了创建伪真实数据集的方法,可以用来训练其他人体模型
HSMR擅长处理难度大的场景,比如复杂的跳舞/运动姿势、拍摄角度不好的照片等
代码:https://github.com/IsshikiHugh/HSMR
控制全尺寸人形机器人
控制人形机器人很困难,尤其是当任务需要全身运动时。
该系统将基于智能学习的策略与低成本可穿戴设备相结合,让一个人能够平稳而精确地控制机器人的手臂、腿部和手部。
这个系统的突出之处在于:
- 实时行走、蹲下和移动手臂。
- 操作员佩戴外骨骼手臂、手套和脚踏板。
- 通过强化学习进行训练,不需要动作捕捉数据。
- 比传统的逆运动学控制更稳定、更快。
这个开源系统展示了将智能人工智能与简单硬件相结合如何使人形机器人控制更加自然和强大。
Project: https://homietele.github.io
Github: https://github.com/OpenRobotLab/OpenHomie
Paper: https://arxiv.org/abs/2502.13013
腾讯开源 FlashVDM:加速 Hunyuan3D 2.0 模型生成速度 30 倍
FlashVDM 是一种专门用于加速形状生成的通用框架,现已开源。
腾讯表示,Hunyuan3D 2.0 整个系列的模型生成速度提升了 30 倍,处理时间从 30 秒缩短至 1 秒。完全得益于 FlashVDM,它不仅支持混元系列模型,还支持加速其他模型。
https://agep-week.oss-cn-hangzhou.aliyuncs.com/2025/202504031709897.mp4
利用chatgpt 4o的画图新能力快速生成手办效果图,然后给到这个模型去生成3D模型

Runway 发布 Gen-4 视频模型:突破跨镜头一致性难题
Runway 最新发布了 Gen-4 视频生成模型,
是继 Gen-3 Alpha 之后的重大升级,主要是解决了 AI 视频生成中的一大难题——角色、物体和场景在不同镜头中的一致性问题,另外在真实感和可控性也有改进。
目前该版本已面向付费用户开放,更多详情可查看官方博客。
字节即梦 3.0 图像模型灰度测试
字节跳动的的 AI 创作平台即梦的生图模型 3.0 正在灰度测试,部分用户有使用权限,从现有用户反馈来看,能直出商用级的海报,出图质量和生成汉字的能力效果非常好。
AnimeGamer:具有下一个游戏状态预测的无限动漫生活模拟
玩家可以通过自然语言指令与游戏世界互动,体验无尽的冒险。例如,可以让《悬崖上的金鱼姬》中的宗介与《千与千寻》中的千寻相遇互动,创造独特的游戏体验。
AnimeGamer 的核心方法包括三个阶段:
- 动画镜头建模:使用动作感知的多模态表示,通过编码器训练扩散解码器来重建视频。
- 下一游戏状态预测:训练 MLLM,利用历史指令和游戏状态表示来预测下一个游戏状态。
- 解码器优化:通过将 MLLM 的预测作为输入,进一步优化解码器,以提高生成视频的质量。
论文:https://arxiv.org/abs/2504.01014
仓库地址:https://github.com/TencentARC/AnimeGamer?tab=readme-ov-file
强大的 PDF 科学论文翻译工具:BabelDOC
它能在保留原文排版的同时提供双语对照,支持复杂论文中的数学公式、表格和图形。
GitHub:https://github.com/funstory-ai/BabelDOC
安装使用简单,并提供易用的命令行界面,同时可使用兼容 OpenAI 模型翻译接口。

GPT 4o 新能力的案例分享
GPT 4o 把渲染器的活也干了

涂鸦与画面主体产生互动

极简主义 3d
