阿里开源LHM:让人物图片动起来
效果类似阿里之前的AnimateAnyone,输入人物图片和参考视频,可以让人物按视频的动作生成视频。
项目地址:https://lingtengqiu.github.io/LHM/
Github:https://github.com/aigc3d/LHM https://t.co/WmlZkVBViZ

一个超级简单的工具, SVG 图标生成 3D 模型
GitHub:https://github.com/lakshaybhushan/vecto3d https://t.co/ljvwzn47zb
作者说他知道你可以在 blender 中将任何 svg 转为 3D 模型,但这个项目让这件事变的更轻松、更快捷。
DeepSeek-V3-0324 现已推出!
DeepSeek 的新版 V3 在非思考/推理模型中排名第二,仅次于Sonnet 3.7。
价格比 Claude 3.7 Sonnet 输入便宜了 21 倍,输出便宜了 53 倍……
(现已在客户端上线)
下图是DeepSeek-V3-0324自己写卡片代码介绍的自己

谷歌Gemini 2.5 Pro出来了,数学、编程和推理能力强,在LMArena上排名第一
特点是具备思考能力,在回答前进行推理思考
在Humanity’s Last Exam上得分18.8%,超o3-mini
上下文窗口100万token(即将提升到200万) 编程比2.0有提升,擅长创建具有视觉吸引力的网页应用和应用,以及代码转换和编辑
可处理包括文本、音频、图像、视频甚至整个代码库等多模态输入
下图是Gemini 2.5 Pro自己写卡片代码介绍的自己

03-25 Open AI 更新了 GPT-4o 的图像生成功能
新绘图功能是真正“有用”的生图工具,是真正的生产力工具;
他真正强大的地方是几乎可以通过自然语言对话完成现在复杂的 SD 图像生成工作流的所有玩法。
比如:重新打光、扩图、换脸、融脸、风格化、风格迁移、换装、换发型还有你能想到的所有。
当然现阶段复杂图像生成流程做不到的他也能做到,后面会展示几个。
没想到很多图像工作流玩法这就都没用了。
举例:
将第一张 Sam 的图片变成第二张葫芦娃的风格,需要保留服装和人物抽象特征,脑袋带上葫芦



风格转换:将这张图片的 Sam 变成皮克斯 CG 3D Q 版的风格


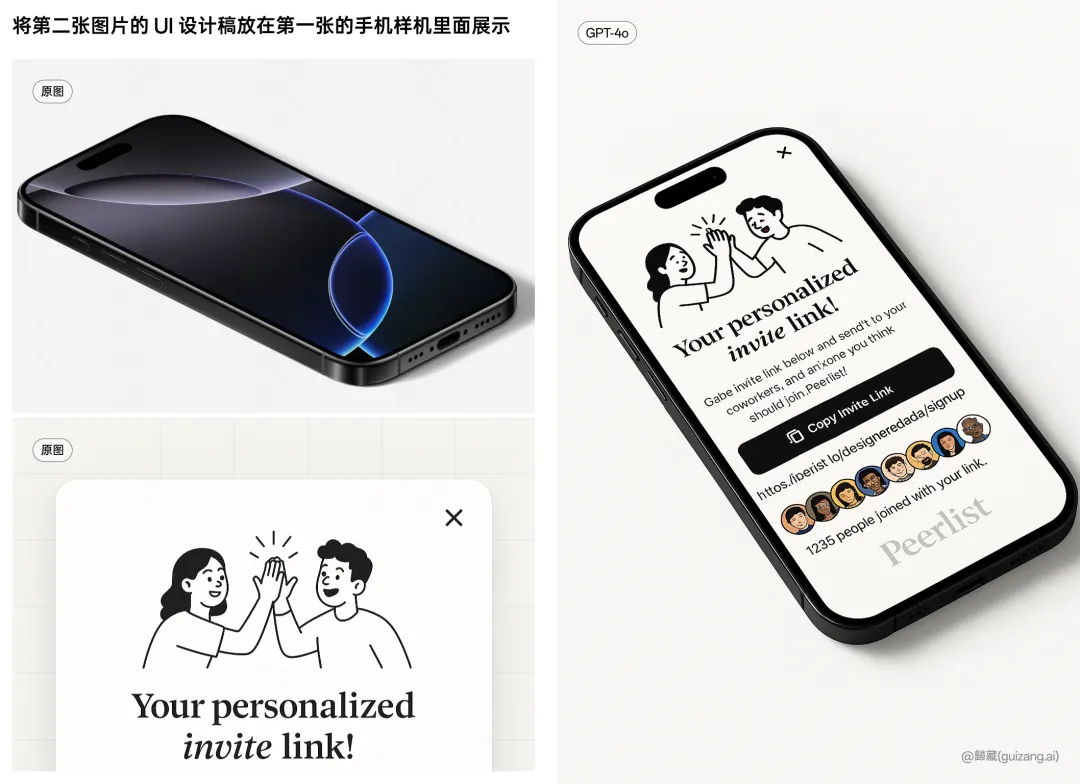
直接让他修改 UI 设计稿,或者直接生成 UI 设计稿。
提示词1:将这张图更改为蓝色氛围,星星图标改为魔法棒图标,同时将里面文案描述的主题改为其他的
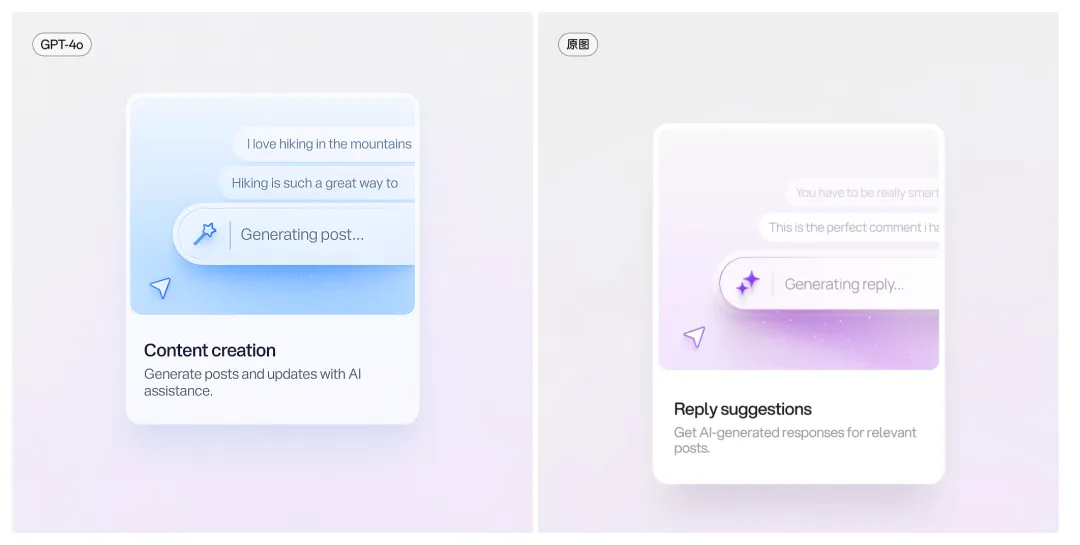
提示词 2:帮我生成一张这样的 UI 设计稿:Peerlist邀请链接界面分析,界面内容。。。
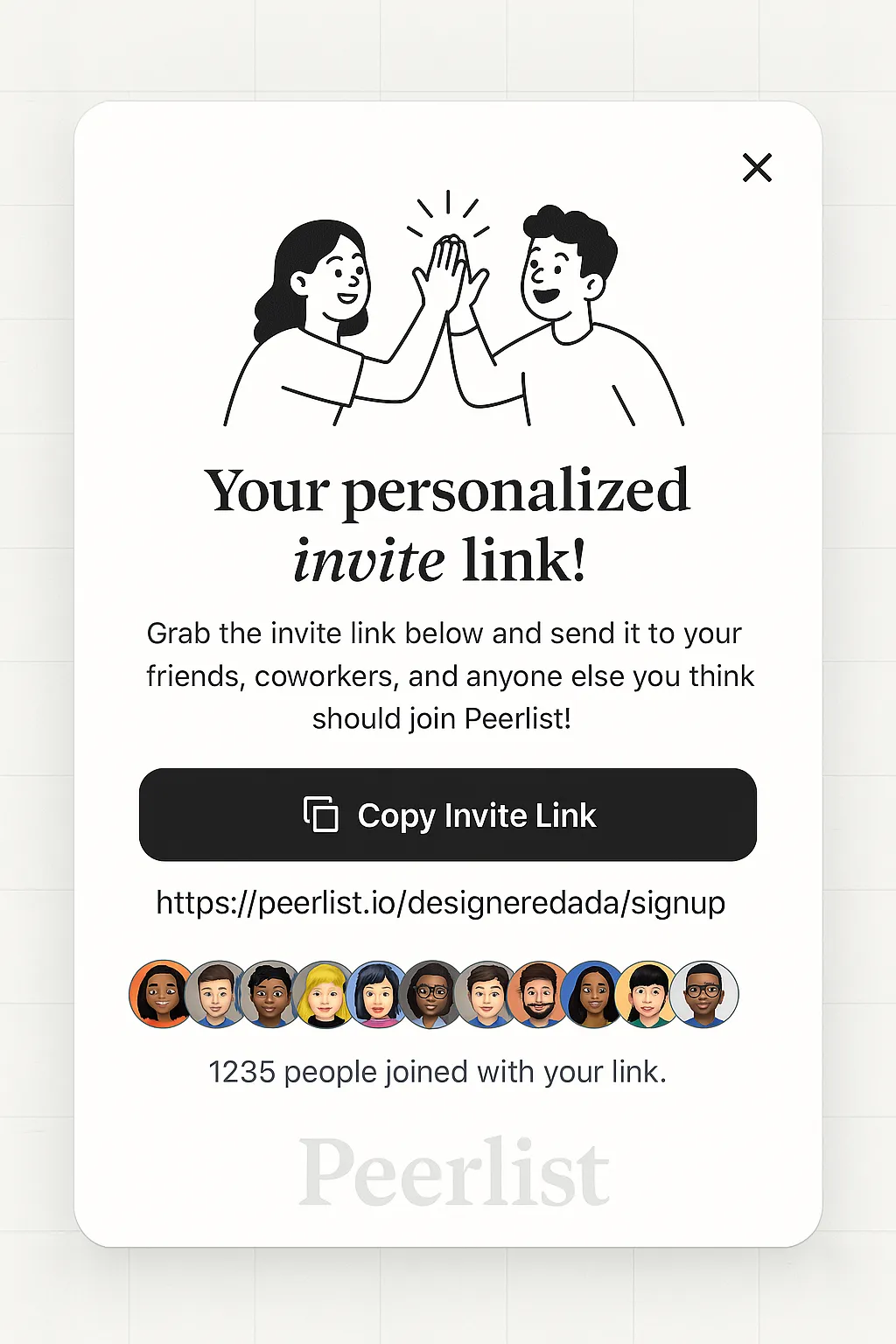
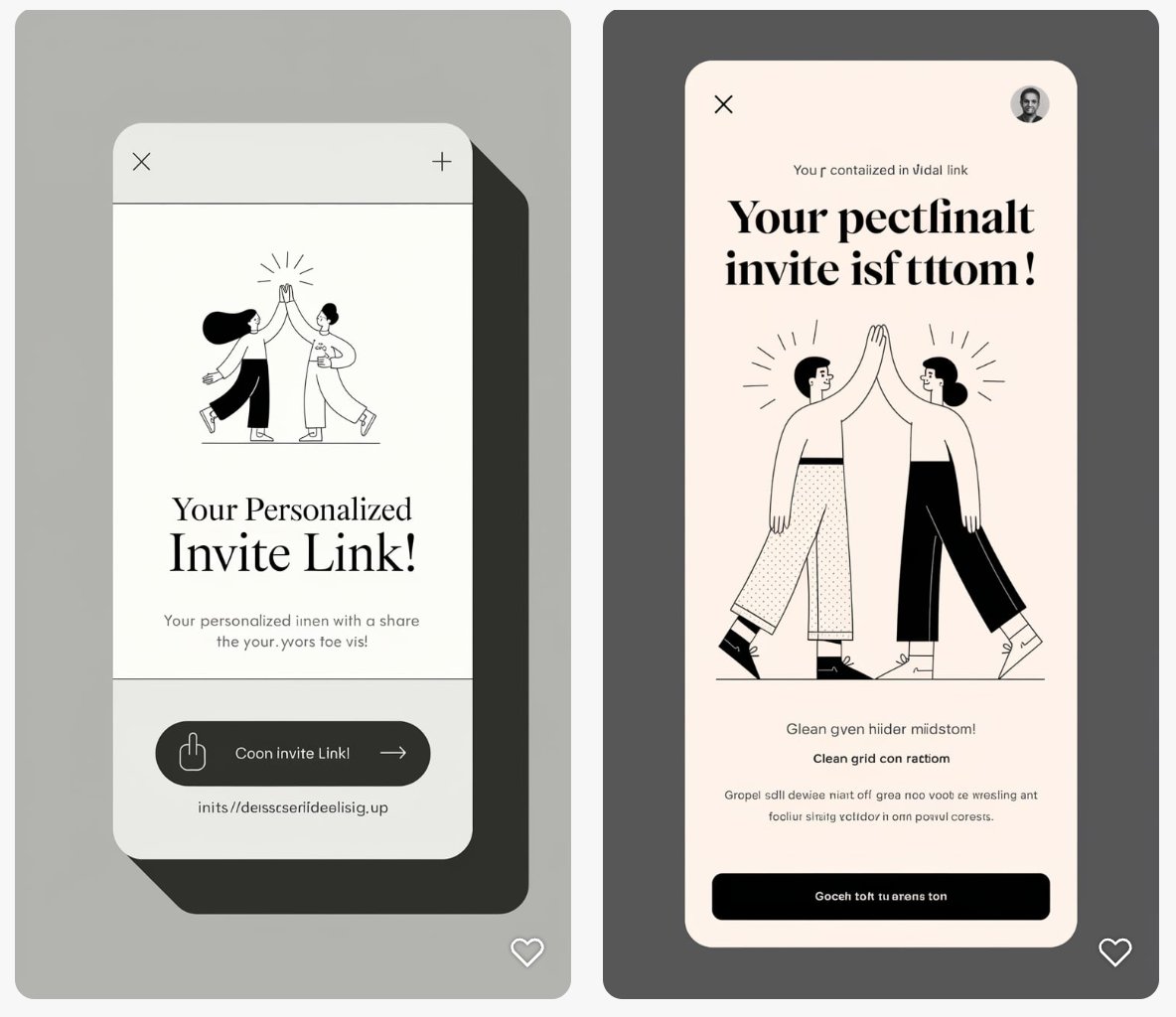
最后你甚至可以为你的设计稿加上样机。
制作自己的表情包(可以是IP的表情包)

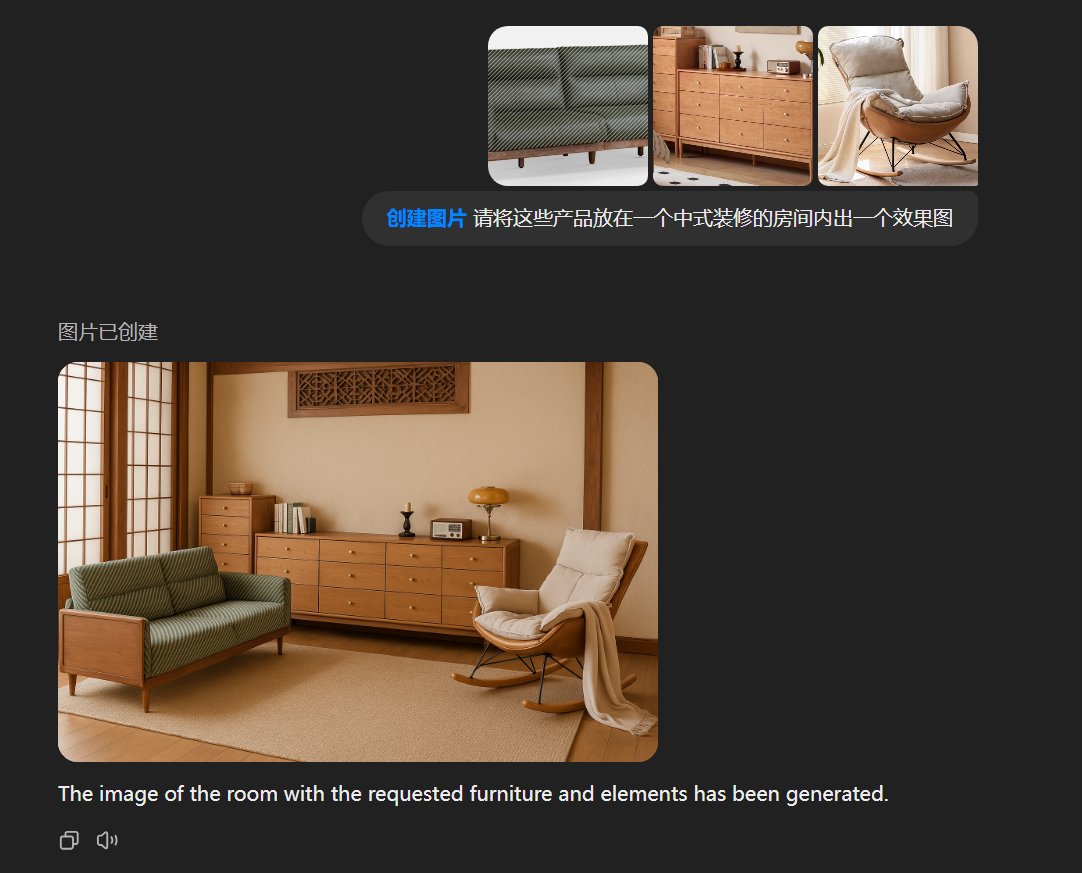
产品赋能(像之前的徐总的产品宣传手册的图就可以现在简单完成)
从商家端: 只需要拍实物图, 一句话打造各种场景的效果图; 从用户端: 可以选个各种家具让他组合搭配看效果图
下面的图的细节,GPT-4o 将原图桌上的书本换成了 Peace Sattlement,这说明他知道这张图具体是什么意思,经过思考后才出的图


总结:GPT-4o 的绘图能力是模型原生的,而不是像以前那样简单去调用 Dall-E,而是经过思维链思考后结合自己的知识去反馈你的指令
03-28 GPT-4o 在 ChatGPT 中再次升级了
具体有哪些新变化?
- 更擅长理解并执行详细的指令,尤其是同时包含多个请求的提示。
- 在处理复杂的技术问题和编程任务时表现更佳。
- 直觉和创造力进一步提升。
- 更少使用表情符号 🙃
升级后的 GPT-4o 现已对所有付费用户开放,免费用户将在未来几周内陆续体验到。
在 LMSYS竞技场排名第2,仅此于刚发布的Gemini 2.5 Pro,超越GPT 4.5
- 与 1 月版本相比有显著改进(跃升30 点,排名#5->#2)
- 在编码、硬提示中并列 #1,所有类别的前 2 名
- 性能超越 GPT-4.5,但价格仅为其 1/10
与之前的 版本相比,改进明显:
- 数学 #14 -> #2
- 硬提示 #7 -> #1
- 编码 #5 -> #1
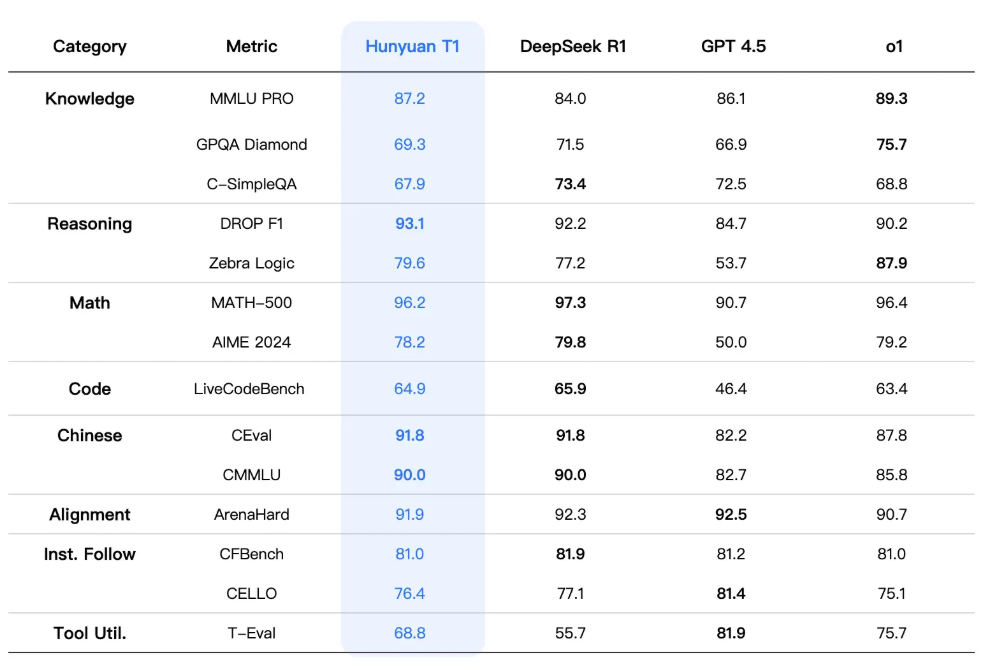
腾讯混元 T1:首个 Mamba 与 Transformer 结合的推理模型
腾讯近日发布了混元 T1 模型,这是业内首个将 Mamba 和 Transformer 结合的推理模型。
在数学和编程方面比DeepSeek R1要差点,其他指标基本持平或略超R1。
这个模型没有开源,不过提供了 API ,而且价格相当便宜,每百万输入 tokens 1 元,每百万输出 tokens 4 元,约为 DeepSeek R1 标准时段价格的四分之一。
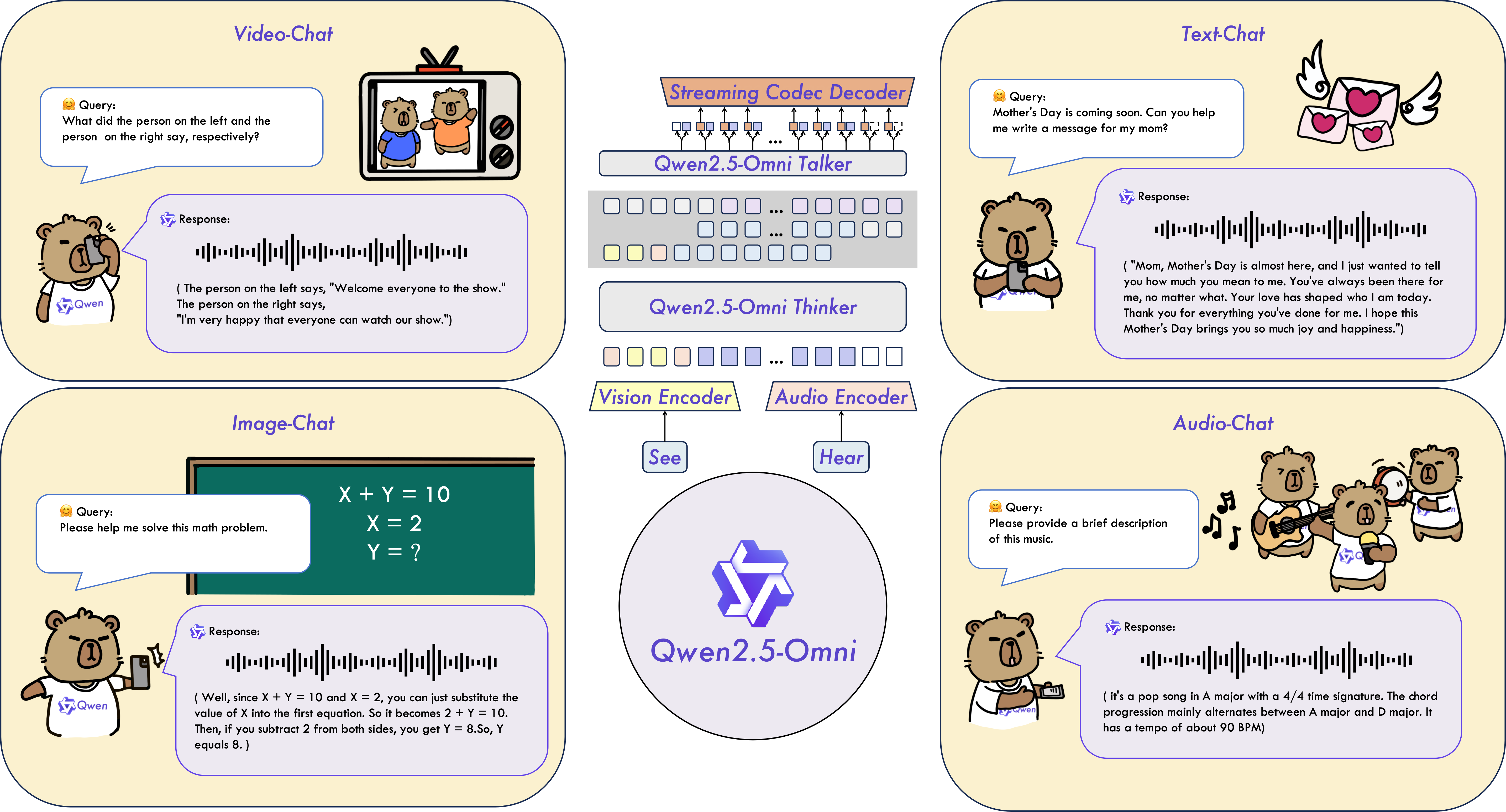
阿里通义团队发布了 Qwen 2.5-Omni-7B 模型,OpenAI 高级语音模式的开源平替。
Qwen 2.5-Omni是一个端到端的多模态大语言模型,旨在感知包括文本、图像、音频和视频在内的多种模态,同时以流式的方式生成文本和自然语音响应。
主要特点
- 全能创新架构:我们提出了一种全新的Thinker-Talker架构,这是一种端到端的多模态模型,旨在支持文本/图像/音频/视频的跨模态理解,同时以流式方式生成文本和自然语音响应。我们提出了一种新的位置编码技术,称为TMRoPE(Time-aligned Multimodal RoPE),通过时间轴对齐实现视频与音频输入的精准同步。
- 实时音视频交互:架构旨在支持完全实时交互,支持分块输入和即时输出。
- 自然流畅的语音生成:在语音生成的自然性和稳定性方面超越了许多现有的流式和非流式替代方案。
- 全模态性能优势:在同等规模的单模态模型进行基准测试时,表现出卓越的性能。Qwen2.5-Omni在音频能力上优于类似大小的Qwen2-Audio,并与Qwen2.5-VL-7B保持同等水平。
- 卓越的端到端语音指令跟随能力:Qwen2.5-Omni在端到端语音指令跟随方面表现出与文本输入处理相媲美的效果,在MMLU通用知识理解和GSM8K数学推理等基准测试中表现优异。