Manus 的原理
Manus 系统配置的细节:
-
使用的是Claude Sonnet模型 套壳
-
配备了29个工具
-
没有多代理功能
-
使用了"browser_use"这个开源项目
OpenAI推出了一系列新的工具和API
旨在帮助开发者和企业更轻松地构建有用且可靠的AI代理(agents)。以下是OpenAI此次发布内容的总结:
-
Responses API 功能:这是一个新的API,结合了Chat Completions API的简单性和Assistants API的工具使用能力。开发者可以通过单个API调用,利用多个工具和模型解决复杂任务。 内置工具:支持网络搜索(web search)、文件搜索(file search)和计算机使用(computer use)等新工具,帮助模型与现实世界连接。
改进:提供统一的设计、更简单的多态性、直观的流事件以及SDK辅助功能(如response.output_text),提升易用性。 -
**网络搜索工具(Web Search Tool)**功能:允许开发者从网络获取快速、实时的答案,并提供清晰的引用。
-
**文件搜索工具(File Search Tool)**功能:从大量文档中检索相关信息,支持多种文件类型、查询优化、元数据过滤和自定义重排序。
-
**计算机使用工具(Computer Use Tool)**功能:通过捕获模型生成的鼠标和键盘操作,自动化计算机任务。 技术基础:基于Computer-Using Agent (CUA)模型,在OSWorld(38.1%)、WebArena(58.1%)、WebVoyager(87%)等基准测试中刷新纪录。
-
Agents SDK功能:一个开源SDK,简化多代理工作流的编排,改进自Swarm SDK。 特性:可配置代理(带指令和工具)。 智能代理切换。 可配置安全检查。 执行追踪,便于调试和优化。 适用场景:客户支持自动化、多步骤研究、内容生成、代码审查。
MCP,可以让 Claude 可以直接控制 Blender
使用提示词就能创建漂亮的 3D 场景 视频是一个“低多边形龙守护宝藏”场景的演示
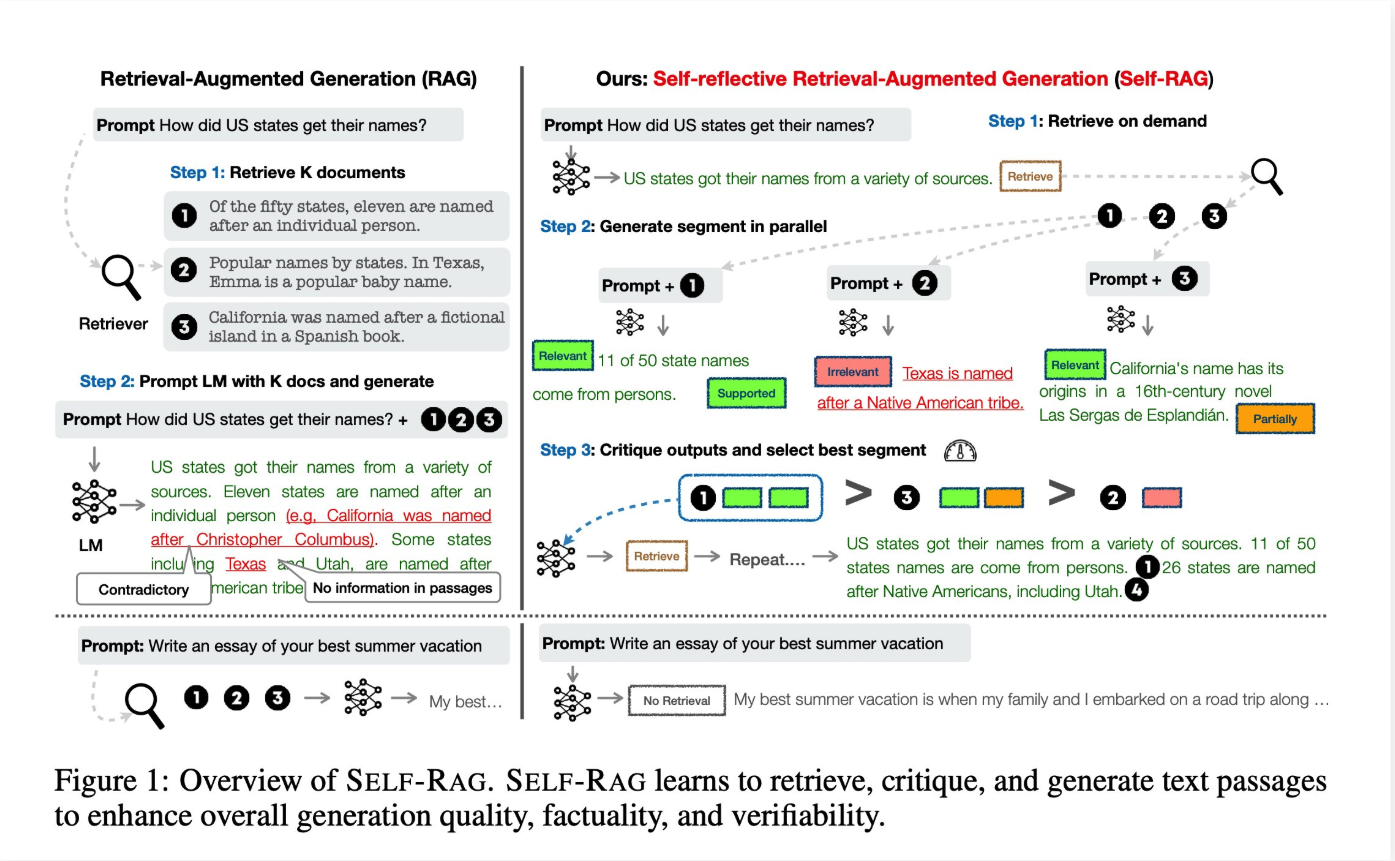
Self-RAG 一种增强型生成模型方法,旨在通过自我反思机制提高生成内容的质量和准确性
Self-RAG的工作原理可以概括如下:
- 检索阶段:像传统的RAG一样,模型首先从外部知识库或数据源中检索相关信息,以补充输入上下文。
- 生成阶段:基于检索到的信息和输入,模型生成初步的回答或内容。
- 自我反思:模型会对自己的生成结果进行评估,检查是否存在事实错误、不一致性或不完整的地方。这可能通过内置的评判机制或额外的验证步骤实现。
- 迭代改进:如果发现问题,模型会调整生成策略(比如重新检索信息或修正表述),然后生成更高质量的输出。
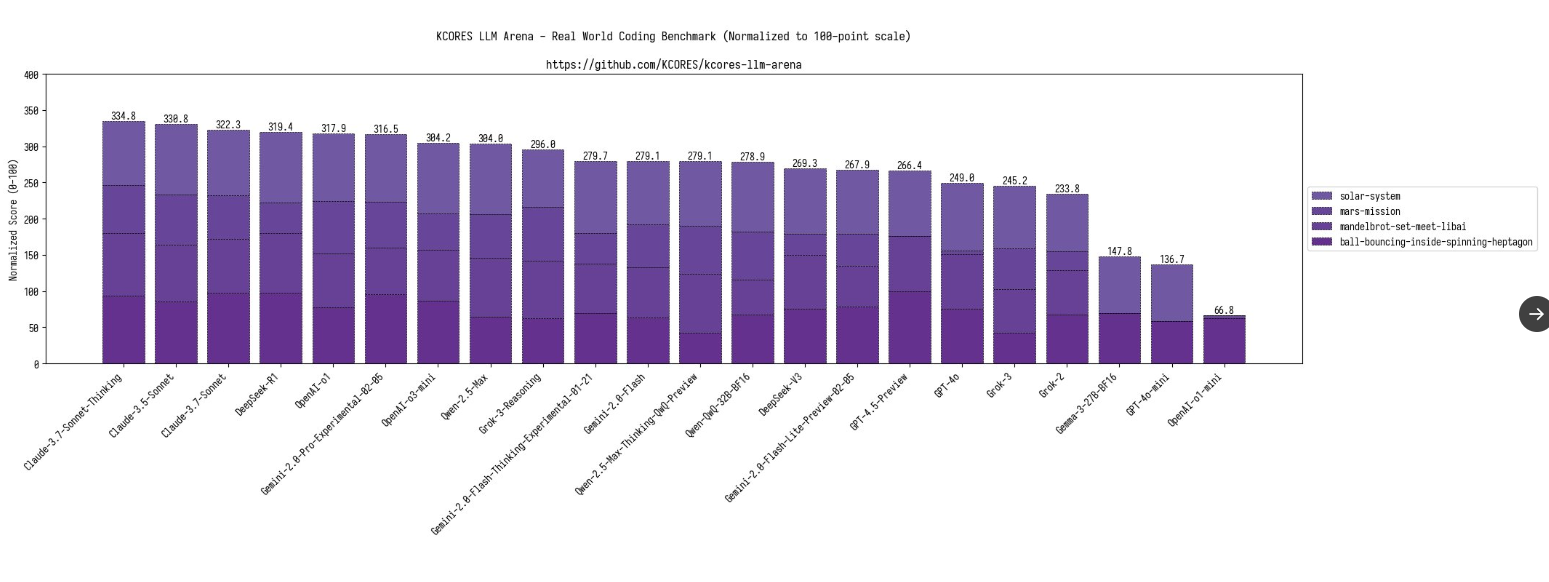
Google Gemma 3:开源大模型支持图像理解
- 能理解 140 多种语言
- 多模态图像和视频输入
- LMArena 分数 1338!
- 128k的上下文窗口
但是效果一般,在4项编程测试中: 火星任务写得python代码有问题,无法运行,直接0分。 Mandelbrot-set-meet-libai 无法渲染有效的 mandelbrot-set图形,0分 太阳系动画模拟,地球运动速度过快以及计算错误,导致垫底,70分 20小球碰撞模拟,小球掉出了7边形,但比其他的只能渲染出来一个小球的模型好一些,63分。
谷歌发布 Gemini Embedding 模型
Gemini Embedding 是谷歌最近推出的一个实验性嵌入模型(gemini-embedding-exp-03-07),通过 Gemini API 提供服务,该模型在多语言文本嵌入基准测试(MTEB)排行榜上排名第一,超越了之前的 text-embedding-004 模型。
Gemini Embedding 支持长达 8K token 的输入,能够嵌入更长的文本、代码或其他数据,输出维度为 3K,几乎是之前 Embedding 模型的四倍。
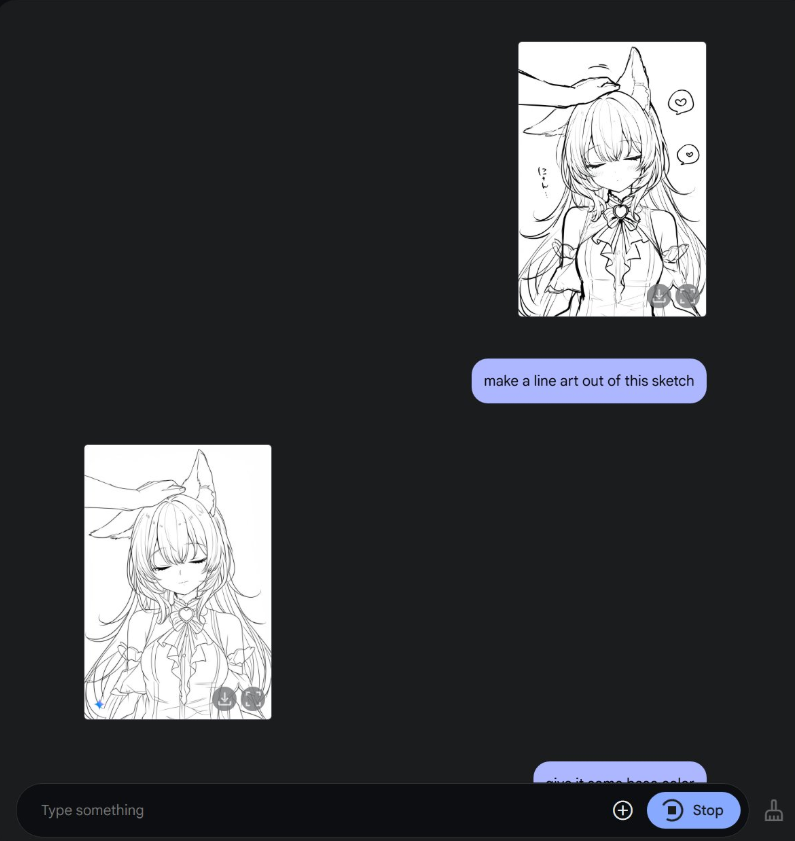
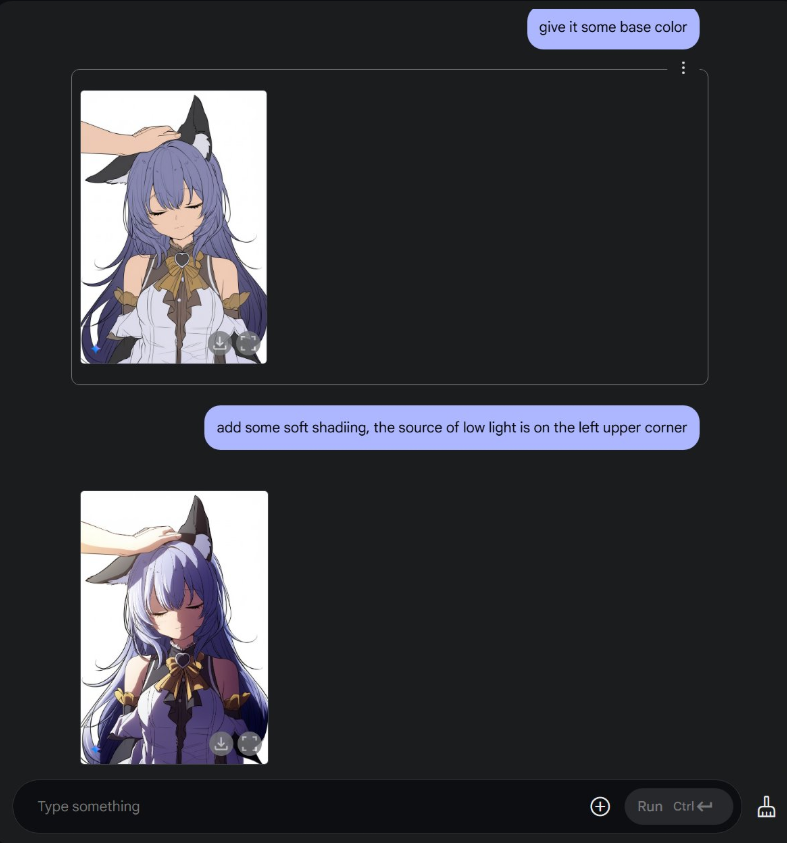
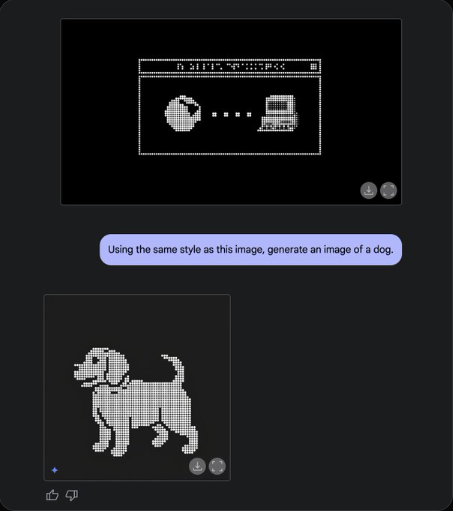
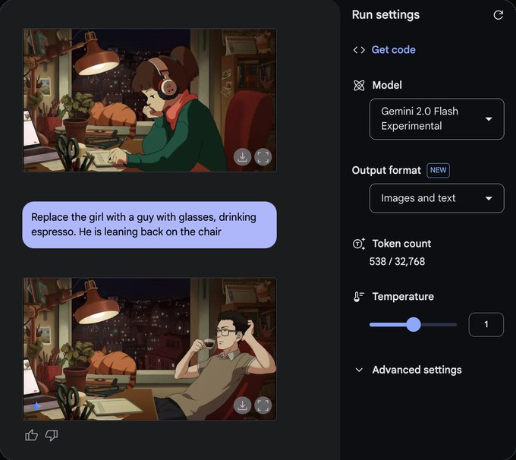
谷歌 Gemini 2.0 Flash 原生图像生成功能正式开放
谷歌的 Gemini 2.0 Flash 的原生图像生成功能现已正式开放。该功能首次测试于 2024 年 12 月,现在,开发者可以通过 API 或 AI Studio 的界面测试 Gemini 2.0 Flash EXP 模型的图像生成和编辑功能。
与 Stable Diffusion、Flux 不同,Gemini 2.0 Flash EXP 模型不仅能够通过自然语言生成图片,还能将图像与文本混合输出,甚至支持多轮对话保证人物主体性,逐步调整和优化图像。
Google DeepMind 推出基于 Gemini 2.0 研发的新一代 机器人 AI 模型
无需专门训练,即可适应新的任务、物体和环境 一共核心 AI 模型: Gemini Robotics :具备“视觉-语言-动作”能力,可直接控制机器人执行任务 Gemini Robotics-ER :具备 空间理解、具身推理能力, 它能让机器人更好地理解周围环境,例如识别物体及其可交互部分(如杯子的把手),并规划行动路径。
Gemini Robotics 的主要特性:
-
泛化能力:Gemini Robotics利用Gemini 2.0的世界理解能力,机器人能够处理未见过的新物体、新指令和新环境,甚至完成训练中未见过的新任务。在综合泛化基准测试中,Gemini Robotics的性能比其他最先进的VLA模型高出一倍以上。例如,它能完成未训练过的任务,如扣篮一个新篮球。
-
交互性:它能理解日常语言指令(包括不同语言),并快速响应环境或指令的变化。例如,当物体被移动时,它能迅速重新规划行动路径,无需额外输入即可继续任务。
-
灵活性与灵巧性:通过多模态推理(结合视觉、语言和动作),机器人能精确操控物体,完成多步骤任务。支持执行需要精细动作的复杂任务,如折叠纸鹤、将零食装进拉链袋或轻柔放置眼镜。
-
多形态适应:Gemini Robotics不仅限于特定机器人类型,它可以适配从双臂机器人平台(如ALOHA 2)到人形机器人(如Apptronik的Apollo)的多种形态。
Same dev像素级精度复制任何UI界面
并生成前端代码 只需提供网页 URL、截图或设计文件(如 Figma),Same dev即可生成对应的代码,确保视觉效果与原始界面高度一致。
Same dev宣称可以以像素级精度复制任何用户界面(UI)。 我跑了下免费额度很快被消耗完了, 模式有点类似manus,也是在云端电脑上跑,自定编码。
是基于Claude 3.7的,消耗完需要输入API。
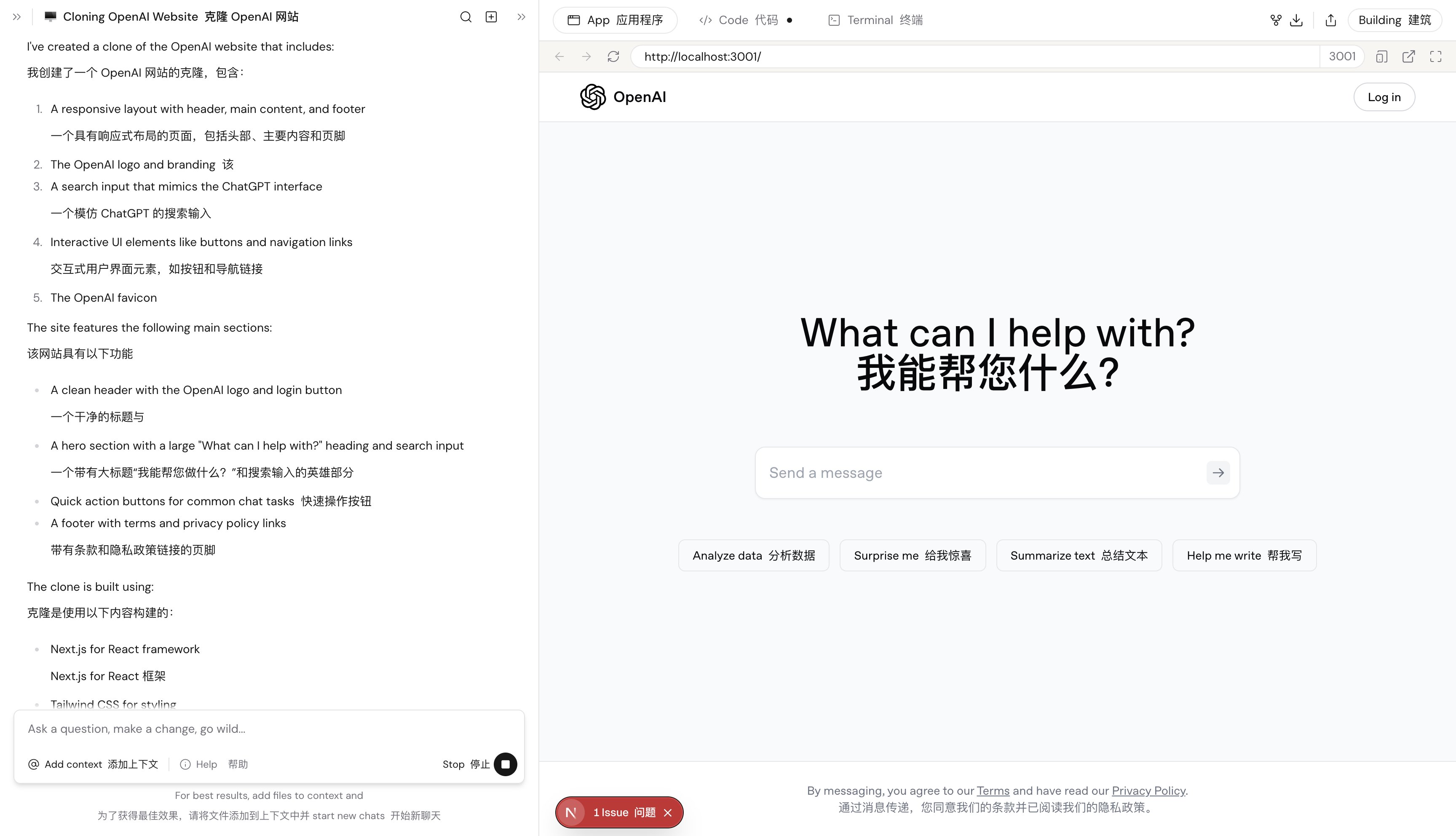
下面是复制的openai网站: