文档提取/转换 工具MinerU
支持在线使用或通过本地客户端+API方式调用
也可以私有化部署到本地 支持PDF、Word、PPT等多种文档的智能解析,可用于机器学习、大模型语料生产、RAG等场景
可以利用这个做多模态文本处理 不过目前还未支持语义切块处理
DiffRhythm:全球首个基于扩散模型的端到端音乐模型
能力:
- 能够在 10 秒内生成一首完整包含人声和伴奏的歌曲
- 端到端自动生成完整歌曲(无需人工干预)
- 输入歌词 + 风格提示,即可生成完整音乐
- 10 秒生成一整首 4 分 45 秒歌曲(人声 + 伴奏)
- 高质量音乐,歌词与旋律同步自然 基于扩散变换器(DiT),避免传统自回归模型(LLM)慢速推理问题
相比 MusicLM,DiffRhythm 生成速度快 50 倍
输入: 歌词(例如:“在夜色中,我听见风的声音”)
风格提示(例如:“流行”、“电子”、“爵士”) 即可生成完整音乐
还可以上传音乐片段作为提示来生成相应的音乐风格。
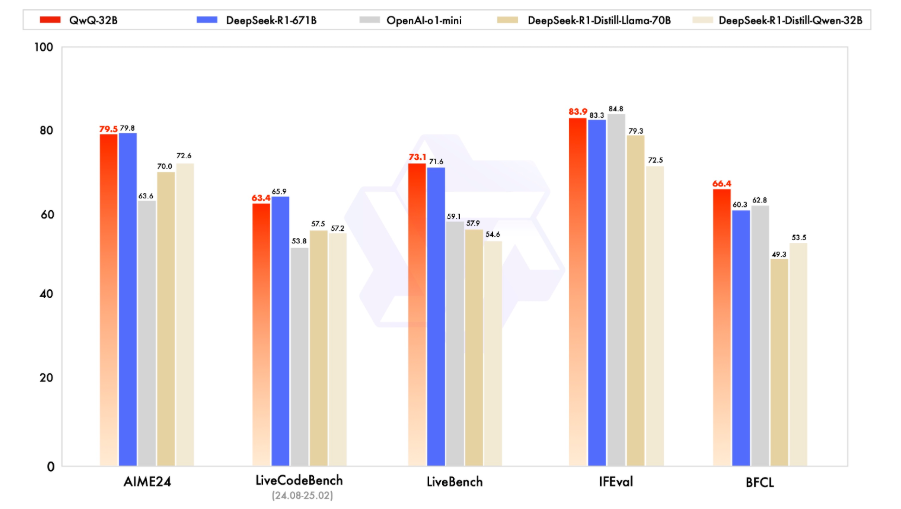
阿里开源 QwQ-32B:320 亿参数推理模型,官方称性能媲美 DeepSeek-R1
阿里开源了其最新的 QwQ-32B 推理模型,这是一款拥有 320 亿参数的先进模型。
QwQ-32B 的性能可与具备 6710 亿参数(其中 370 亿被激活)的 DeepSeek-R1 相媲美,采用了 Apache 2.0 开源协议。
Qwen-QwQ-32B-BF16 目前 KCORES 大模型竞技场测试测试得分为 278.9 分,在榜单中超过了 DeepSeek-V3, 距离DeepSeek-R1 还比较远。 但是!距离线上的 Qwen-2.5-Max-Thinking-QwQ-Preview 仅差 0.2 分!这意味着千问这次开源的的确就是线上水平的版本!
但是,我觉得这个才是更符合普通人或者公司去使用的模型;参数不是那么大,性能也够一般任务。
已上线open-webui,小伙伴们可以体验;
关于manus的pr铺天盖地,号称通用Agent
Manus真正解决的问题:不只是搜索信息,而是实现AI主动探索决策。对比DeepResearch来说:一个是专用模型,研究深度更强,一个是多Agent调用,功能更复杂,但缺点也是幻觉多。
**1、拆解了下manus:**能力是compute use + 虚拟机 + artifacts + 内置一批agent的综合产物。
**2、可行性:**如果不会被模型内化,agent是个个性化的东西,这个manus定位有点想做通用领域的http://bolt.new(http://bolt.new是专注编程任务),明显是完全矛盾,不太可能实现
**3、可能性:**唯一可能的就是定位为一个新入口,未来整合各种agent、conpute use能力进去,这个工作量极其的大,更看好聚合mcp的协议模式整合,除非走这个路线
**4、局限性:**懂得人受制于局限性可能不屑于用,除非有几个爆款的场景,不懂的人不会用,但是会在自媒体装逼的圈子里火起来。
如果真像宣传所说是通用的agent,那么这些通用能力大概率未来会被大模型内化掉。
同行竞争主要是coze、dify这类,如果这条路通,这些未来也会推出这种路线。
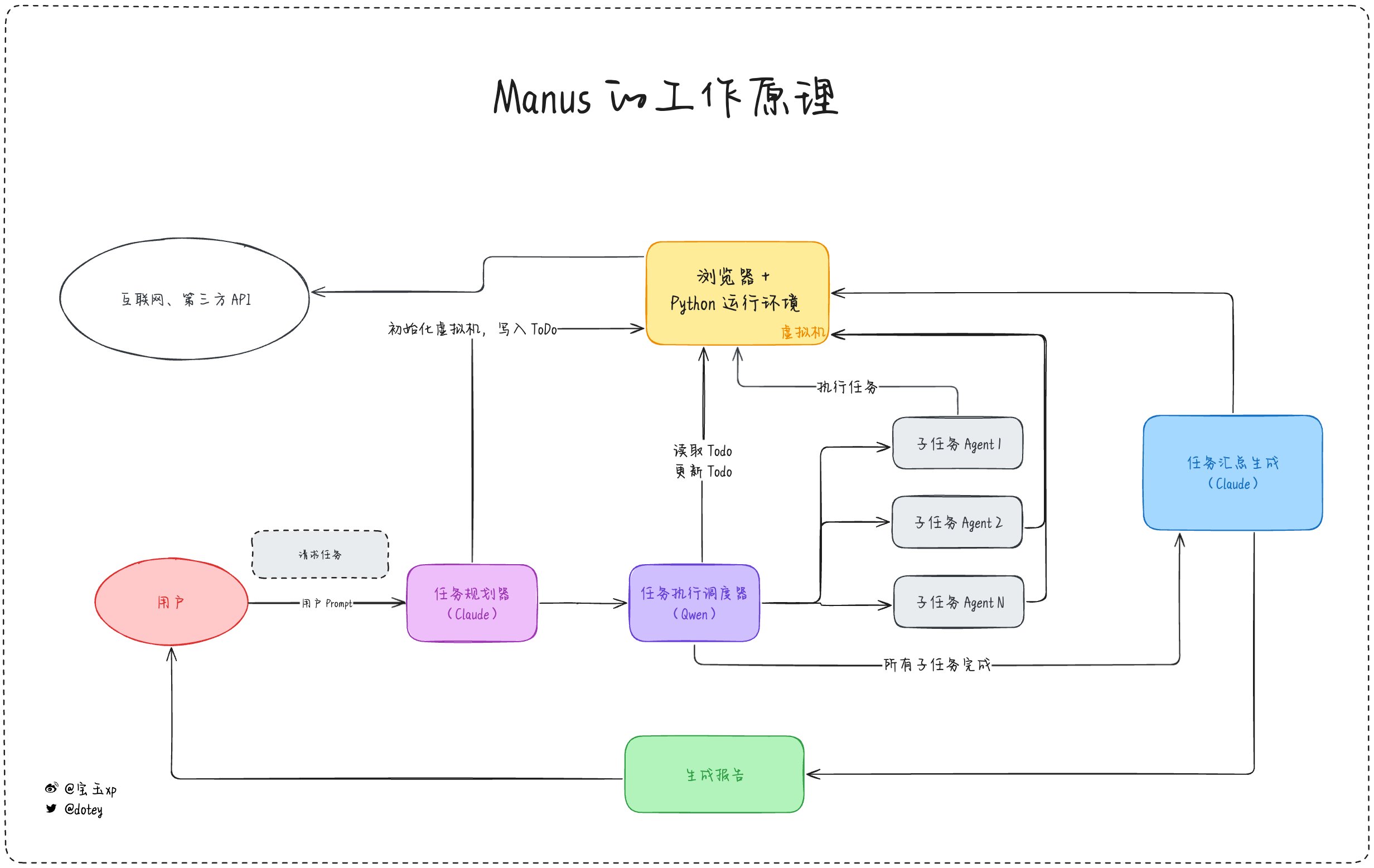
一图胜千言,图1 这里我大致画了一下 Manus 的架构图(不代表真实实现,仅作示意参考),主要有几个模块:
- 虚拟机:一个 Linux 系统的虚拟机,安装有 Chrome 浏览器,用来访问网页 Python 运行环境,可以执行脚本分析数据,可以启动一个网页运行环境
- 任务规划器:根据用户输入的任务请求,拆分成 ToDo List,我推测是 Claude 模型,因为这一步至关重要,必须要求模型有很强的推理能力,目前来说 Claude 3.7 Sonnet 应该是很经济实惠的选择
- 任务执行调度器:根据 ToDo List 的任务清单,逐一执行,根据任务去选择最合适的 Agent。由于这一步重点是在 Agent 的选择,所以不需要能力太强的模型,可以用开源模型比如 Qwen 稍微微调一下就可以用了。
- 各种执行不同类型任务的 Agents:Manus 内置了很多 Agent,比如最复杂的应该是类似于 OpenAI Operator 的网页浏览 Agent,比如根据特定 API 检索特定数据的 Agent,每个 Agent 在完成任务后都会把任务结果写到虚拟机。
- 任务汇总生成器:当每个子任务执行完成后,任务执行调度器就会通知任务汇总生成器,任务汇总生成器就会去虚拟机读取 ToDo List 以及各个子任务的生成结果,把这些结果汇总整理生成最终结果,根据任务要求,可能是一份调研报告,可能是网页程序。由于这一步要求有极强的推理能力和语言能力,所以必然要求一个很强的模型,所以我猜这里也应该是 Claude 3.7 Sonnet。
这基本上就是它的主要工作原理,所以你也可以看得出,真正制约它能力的还是在于模型的能力和 Agent 的能力,而 Agent 也是受制于模型的能力
腾讯发布图像到视频生成模型 HunyuanVideo-I2V
语义理解精准且运动自然
- 多模态理解,结合文本描述和图像信息,让生成的视频更符合用户需求
- 高一致性:确保 视频首帧 与输入图片高度一致,避免失真或风格变化。
- 自然动态过渡:生成流畅的视频运动,支持人物、风景、物体的动态演绎
- 最高支持 720P 视频
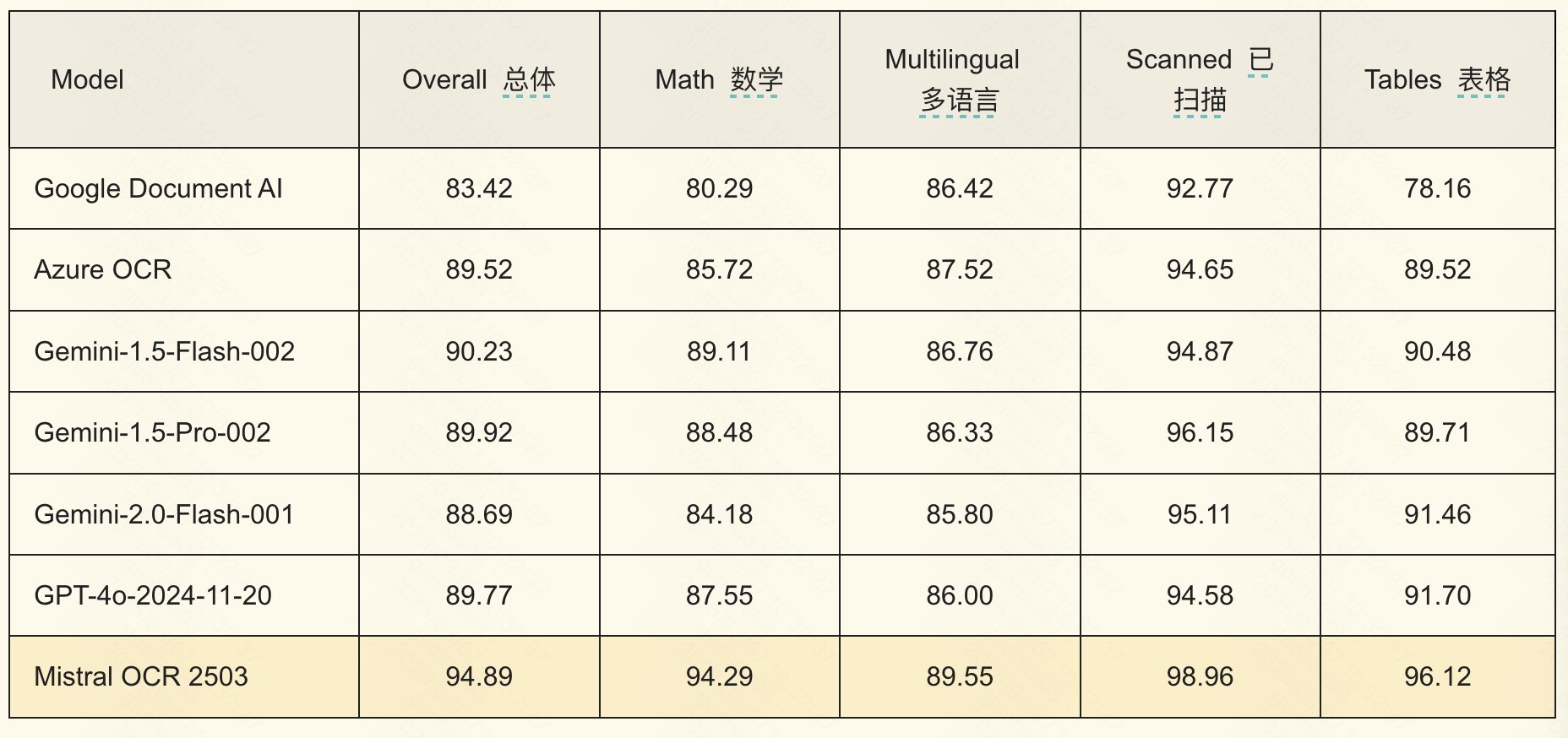
Mistral 发布 Mistral OCR
应该是目前世界上最好的 OCR API
- 理解文档中的每个元素,还原原始文档排版
- 原生支持多语言和多模态
- 同类 OCR 模型中速度最快
- Doc-as-prompt, 结构化输出
- 支持私有化部署
这个模型对各种图片和 PDF 理解帮助太大了
从测试结果来看中文效果相较于其他语言要差一些

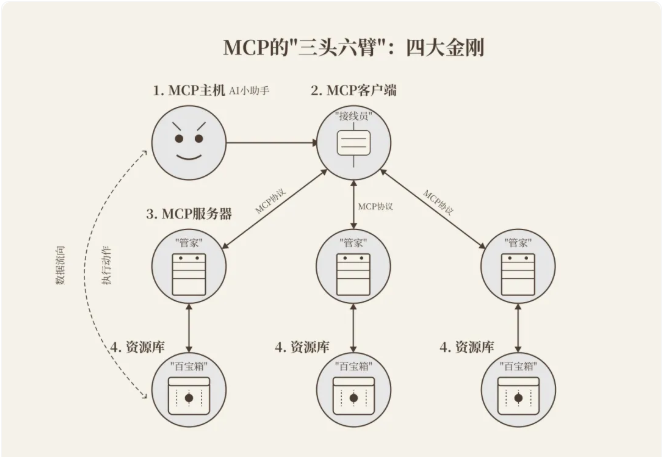
MCP 给AI世界装上“万能插头”
如果AI是个智商爆表但四肢不协调的小天才,那 MCP(Model Context Protocol) 就是给它装上的机械外骨骼,让这位"书呆子"能抬手翻文件、伸腿取快递,甚至帮你“把咖啡都冲好”。
MCP(Model Context Protocol,模型上下文协议)是由Anthropic(Claude母公司)于2024年底推出的AI领域开放协议,其核心目标是解决AI与外部资源交互的标准化难题,被称为AI世界的"万能插头"。
MCP 正常工作需要包含四大部分:
- MCP主机:你的AI小助手(比如 DeepSeek、ChatGPT、Claude 等)
- MCP 客户端:藏在主机里的"接线员"
- MCP 服务器:掌握资源密钥的"管家"
- 资源库:从本地文件到云端的"百宝箱"
为什么大家集体喊"真香"
-
告别繁琐操作
以前让AI使用各种软件和服务,需要开发者写大量复杂代码;现在有了MCP,只需简单设置就能搞定,省下的时间够撸10只猫 -
数据安全更有保障
像给数据配了个保安一样控制访问范围,AI可控的在你的设备上"隔空取物",大大降低信息泄露风险(当然,可能有人会担心AI偷看私密照片)
-
功能爆炸式增长
从 GitHub 代码库到 Linear(项目管理工具),从联网回答到本地文件…各种MCP插件不断涌现,有人还写了点外卖的插件,就像给AI装上了"千手观音"的手臂,无所不能
-
记忆力大幅提升
AI终于能清晰记住之前的对话内容,有可能像老友记里的钱德勒一样接梗:“还记得上周那个bug吗?我找到它二舅姥爷了!”
Runway 沉寂几个月后终于发了新功能
视频转视频支持增加首帧图片用于进行风格转换
比如更改画风或者天气、季节等