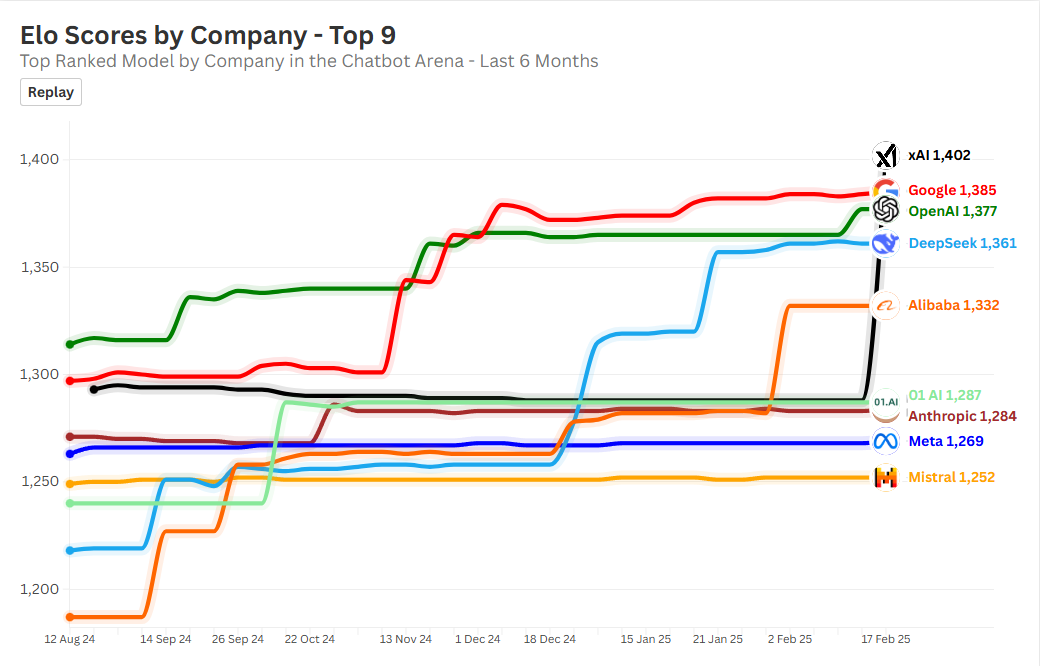
2025 年 TOP9 大模型 Elo 得分趋势:xAI 领跑
在过去的几个月中,AI 大模型的竞争依然非常卷。继上个月 DeepSeek 的几次技术突破后,xAI 凭借其最新的 Grok3 Beta 版一跃登上排行榜首位,成为当前大模型赛道的领跑者。
你可以通过视频看到这些趋势,也可以查看这个在线版 (在线版是会动的图表)提供了 2025 年 TOP9 来自 Chatbot Arena 的 Elo 得分趋势的可视化数据。
第一个前空翻的机器人:众擎
走路步态控制的也蛮像人类的机器人
Unitree G1 的算法升级,使其能够学习和执行几乎任何动作
宇树 Unitree G1机器人 表演中国功夫
DeepSeek开源周,开源的5个仓库
先说官方发布,在统一解释
第 1 天:FlashMLA
为 Hopper GPU 开发的高效 MLA 解码内核,针对可变长度序列进行了优化,目前已投入生产。
BF16 支持 分页 KV 缓存(块大小 64)
H800 上内存受限 3000 GB/s,计算受限 580 TFLOPS
该技术可以让H800计算性能翻倍
第2天:DeepEP
第一个用于 MoE 模型训练和推理的开源 EP 通信库。
第 3 天:DeepGEMM
一个支持密集和 MoE GEMM 的 FP8 GEMM 库,为 V3/R1 训练和推理提供支持。
解读:
可以把整个 AI 计算生态比喻成一个超大型的高铁网络 ,其中英伟达的 GPU 就是高铁列车,而FlashMLA,DeepEP和DeepGEMM 分别解决了高铁网络中的关键环节,使整个系统运行得更高效、更顺畅。
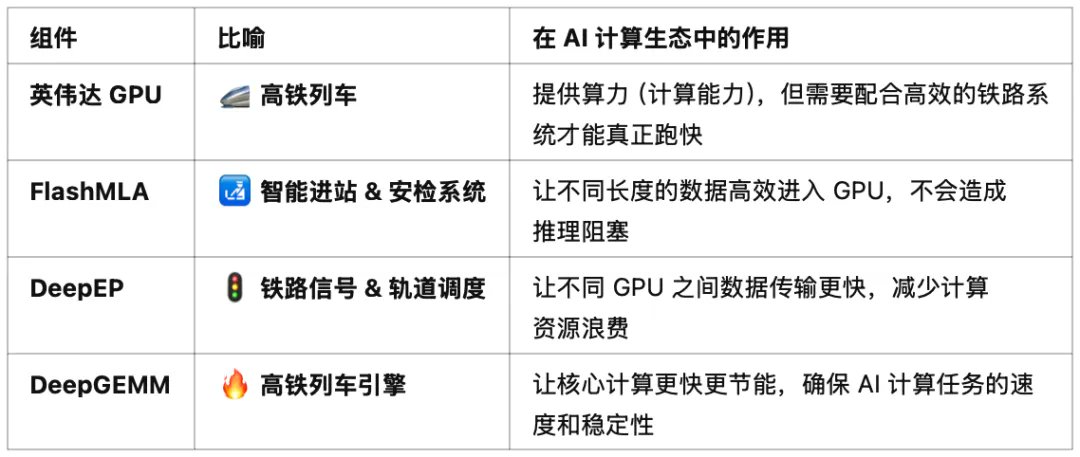
英伟达 GPU = 高铁列车 (算力提供者)
英伟达 GPU 就像提供计算动力的高铁列车,让数据(乘客)快速到达目的地。但如果没有优秀的铁路系统(站点调度、信号控制、高效引擎),再快的列车也会受阻。FlashMLA、DeepEP、DeepGEMM 分别解决了这些问题。
1. FlashMLA = 乘客进站 & 安检优化
FlashMLA 优化推理时的序列长度处理,如同智能高铁进站 & 安检系统:
- BF16 支持: 多种购票方式,加速进站。
- 分页 KV cache: 智能分流安检,避免拥堵。
- 高带宽 & 计算能力: 增加安检通道和速度。
总结: FlashMLA 让数据更快进入计算系统,保证推理顺畅。
2. DeepEP = 铁路信号 & 轨道调度
DeepEP 优化 GPU 间通信,如同高铁信号系统 & 轨道调度中心:
- All-to-All 通信: 优化铁路调度,避免拥堵。
- NVLink + RDMA: 建设高铁专用快车道,核心数据优先。
- FP8 计算支持: 更高效的信号调度,提升整体效率。
总结: DeepEP 确保计算任务像高速列车一样顺畅运行,不会因通信问题停滞。
3. DeepGEMM = 高铁列车的超级引擎
DeepGEMM 优化 AI 核心矩阵计算,如同新一代高铁的高效引擎:
- 1350+ FP8 TFLOPS 计算: 极速发动机,提升计算速度。
- JIT 编译: 智能动力调整,减少能耗。
- 代码精简,性能卓越: 设计简单但效率更高。
- 支持 Dense & MoE: 适应不同规模的计算任务。
总结: DeepGEMM 是超强动力系统,让计算更快、更节能。
这三者的结合,让整个 AI 计算系统像高铁网络一样,高速、稳定、智能地运行!
第4天:DualPipe
DualPipe 是一种创新的双向流水线并行算法,出自 DeepSeek-V3 技术报告,它实现了前向和后向计算-通信阶段的完全重叠,并减少了流水线气泡 (pipeline bubbles)。
第5天:3FS
3FS 的意义在于它为 AI 时代的数据密集型应用提供了一个高性能、可扩展且易于使用的存储解决方案。它解决了传统存储系统在 AI 工作负载中面临的挑战。
通义千文上线Qwen Chat,支持当前所有 Qwen 模型
默认支持 Artifacts,试了一下效果不错 网页搜索、图片上传、语音模式后续会支持 Qwen Chat 基于开源的 Open WebUI 构建
同时也上线qwq的推理功能
点击链接可以前往尝试->http://qwen.ai
阿里巴巴发布全新的开源视频模型Wan2.1
拥有四个不同的型号,支持在个人电脑上运行
超越了众多开源和商业闭源视频模型,最高支持 720P 高清视频。
- 普通消费级 GPU 运行,最低只需要8GB显存。
- 支持多种任务:文本生成视频、图片生成视频、视频转音频等。
- 可以在视频中生成中英文字幕,这是目前大部分 AI 视频生成工具无法做到的。
- 完全开源,Wan2.1 兼顾了视频质量、计算成本和开源优势
测试:
视频展示了一个人在一座白色极简风格的建筑里缓缓地打太极,动作流畅而优雅。背景中,一个巨大的半透明圆形太阳悬挂在天空中,远处,连绵起伏的山峰若隐若现,增添了一份宁静和深远的气息。整个画面充满了和谐与平衡,展现了太极与自然的完美融合。
Anthropic 发布 Claude 3.7 Sonnet 混合推理模型以及 Claude Code 工具
Anthropic 刚刚发布了 Claude 3.7 Sonnet 混合推理模型,拥有200K的上下文窗口,支持高达128K的输出token(测试版),性能超过 DeepSeek R1。支持通过API或 Claude.ai 使用提供服务。
此外,他们还推出了一款面向开发者的命令行工具 Claude Code,目前处于预览阶段,可以帮助开发者直接在终端中完成复杂的工程任务,能搜索和阅读代码、编辑文件、运行测试、提交代码到 GitHub 等。
总结:
Claude 3.5 本身就是 AI 编程实践中的最佳模型。
Claude 3.7 则进一步巩固优势,提升了 20%,妥妥第一了。 并且官方特别强调,这次针对数学和计算机科学竞赛问题的优化较少,而是将重点转向更能反映用户需求的现实任务。
OpenAI 全新 GPT 系列 GPT-4.5 终于来了
GPT 4.5还是基础模型,从基准测试来看比4o提升还是很明显的,性能也是靠近推理模型了!
根据路线图,GPT4.5还是过度模型,最终和GPT 5融合为统一的推理一体模型。
GPT 4.5几乎所有的关键特征都与GPT-4o相同: 它具有相同的128,000个上下文长度,处理相同的输入(文本和图像),知识截止日期,都是2023年10月。
但是GPT-4.5是一个非常大型且计算密集型的模型,使其比GPT-4o更昂贵!
实际的效果提升并不明显,我测了代码方面不如claude 3.7;
在 SimpleQA 基准测试中,GPT-4.5 的得分优于 GPT-4o 和 OpenAI 的推理模型 o1、o3-mini。不过,在编程能力方面,它还是不如 Anthropic 的 Claude 3.7 Sonnet。
对比效果和价格来看,性价比几乎没有,所以不打算接入api

InterMimic 是一项旨在实现基于物理的人机交互的通用全身控制的技术
人形机器人掌握可扩展的运动技能,以适应日常互动
全身运动,针对不同的任务和物体、物理上合理的 HOI 动画
InterMimic 是一种让虚拟角色在模拟环境中,像真人一样与各种物体进行逼真互动(基于物理引擎)的技术