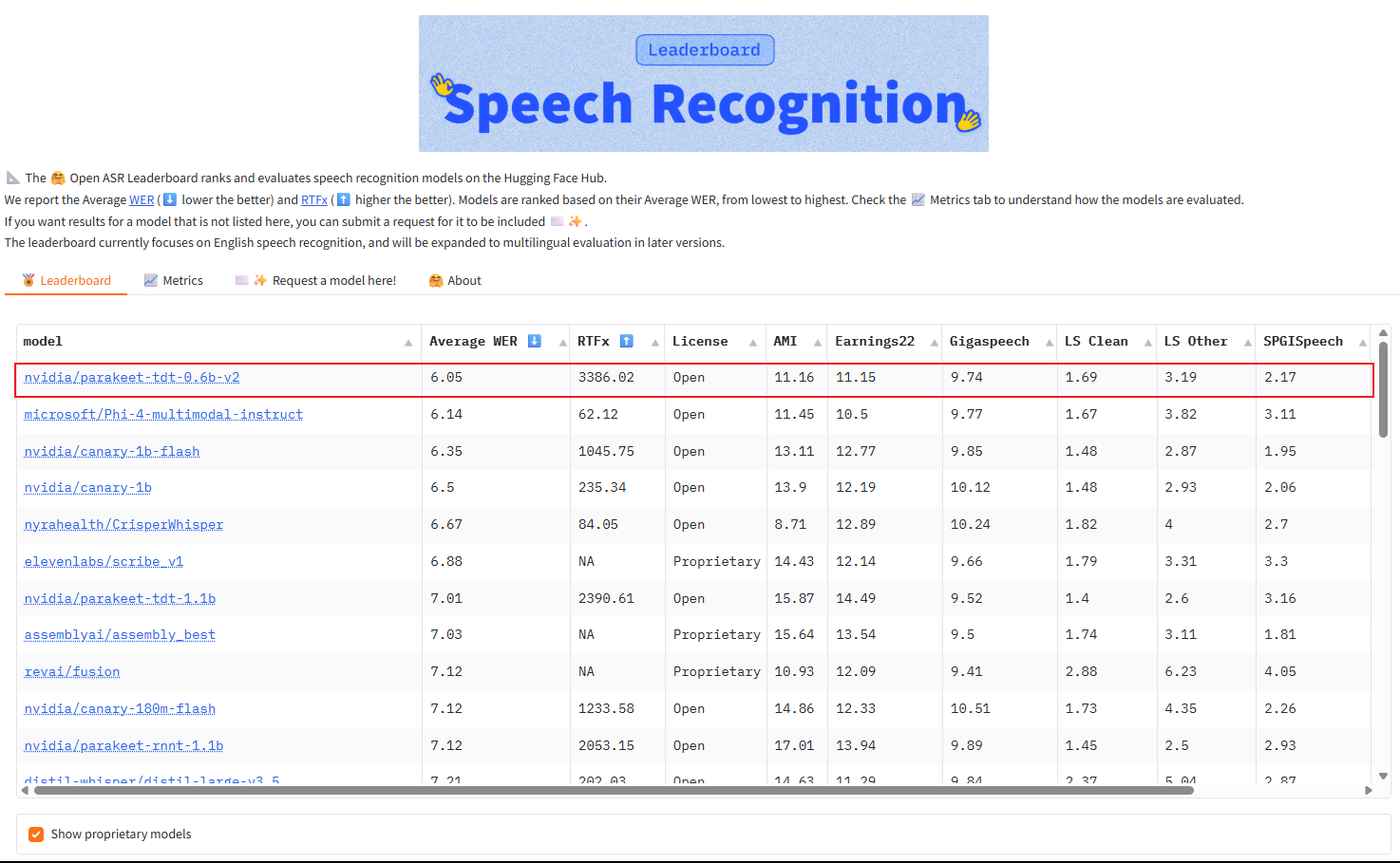
英伟达开源了一个超强的语音识别模型:Parakeet TDT 0.6B V2,登顶 OpenASR 榜单。
它能够在 1 秒内实现高质量转录 60 分钟的音频,而且参数仅仅 0.6B,轻松击败了所有主流闭源模型。
模型下载:http://huggingface.co/nvidia/parakeet-tdt-0.6b-v2
排行榜单:http://huggingface.co/spaces/hf-audio/open_asr_leaderboard
不过目前仅支持识别英文,采用的是 CC-BY-4.0 开源许可,允许商业使用。
Midjourney 推出 Omni-Reference 功能,定向生成更自由!
- 全新 Omni-Reference(全向参考)功能允许用户在生成图像时明确指定“把这个东西放进去”,可将参考图像中的人物、动物、物体等元素直接嵌入生成画面中。
- 支持包括角色造型、风格元素、道具装备在内的多类型参考对象,且可同时上传多张图像,实现多个角色或元素同图协作。
- 该功能是 V6 版本中角色参考功能的升级版,可与个性化、风格化、风格参考图、情绪板等功能组合使用,创作空间显著扩大。

KREA AI:用“画”的方式告诉 ChatGPT 怎么改图!
- KREA AI 引入视觉化提示方式,用户可以通过编辑标记、基本形状、注释和参考图,直接在图像上“指哪改哪”,快速指导 ChatGPT 进行图像编辑。
- 背后基于 GPT 的 image API 实现,展示了文本+视觉交互的新玩法,不再只是打字生成,而是“用图交流”。
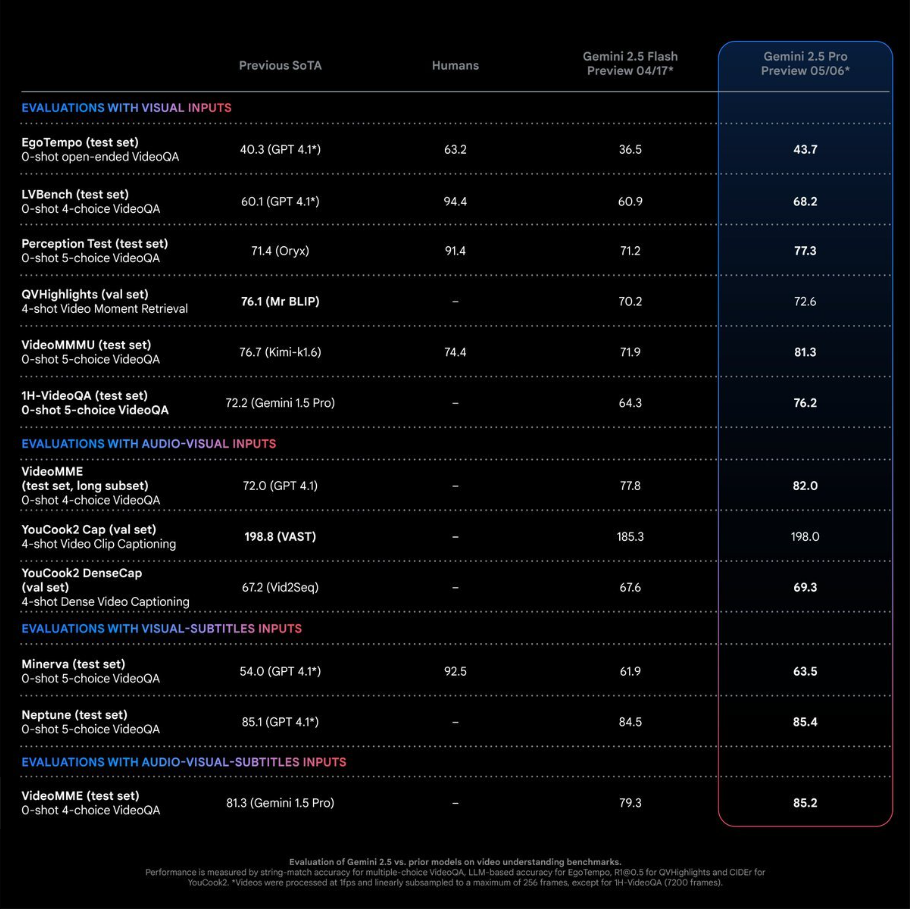
谷歌发布 Gemini 2.5 Pro I/O 特别版:编程双榜第一
谷歌正式发布 Gemini 2.5 Pro "I/O 特别版"技术预览。作为 2.5 Pro 的重大升级版本,其编程能力获得突破性提升 —— 不仅在 LMArena 编码排行榜登顶,更在 WebDev Arena 排行榜稳居第一。
完整更新内容可查阅谷歌官方技术博客。
同样可以在 ai.dev 中直接用,选 Gemini 2.5 Pro Preview 05-06
对于视频的理解是独一份的,甚至在一些测试集上的效果已经超过人类
下面是一个令我震撼的例子:
“根据视频还原动态的网页交互:点阵交互动画设计不错就直接把视频扔给 Gemini 还原并且没好好写提示词”
OpenAI的强化微调上线了-OpenAI o4-mini
在去年12月OpenAI连续12天发布会的第二天提到的强化微调(Reinforcement Fine-Tuning, RFT)的技术;
回到之前发布会上原话解释:
“再次强调,这不是传统的微调。
这是强化微调,它真正利用了强化学习算法,将我们的模型从高中学生水平提升到了专家博士水平。”
强化微调利用了强化学习算法,可以将AI模型从高中学生水平轻松提升到了专家博士水平。
通过强化微调,你可以轻松将模型的某一个领域的专业能力迅速提升,打造出各种AI专家
比如 AccordanceAI基于 o4-mini 强化学习微调在税务场景平衡成本的同时达到了 SOTA
SOTA,全称「state-of-the-art」,用于描述机器学习中取得某个任务上当前最优效果的模型。例如在图像分类任务上,某个模型在常用的数据集(如 ImageNet)上取得了当前最先进的性能表现,我们就可以说这个模型达到了 SOTA。
唯一的缺点是,没有办法私有化;所有的数据都会存储在OpenAI里
RAG 与 Agentic RAG 的对比
RAG 是一种结合了检索(Retrieval)和生成(Generation)的架构,常用于构建知识增强的问答系统或语言模型。
Agentic RAG 是在 RAG 基础上的扩展,引入了“智能体行为(Agentic Behavior)”,使系统具备多轮推理、主动规划、工具调用等能力。