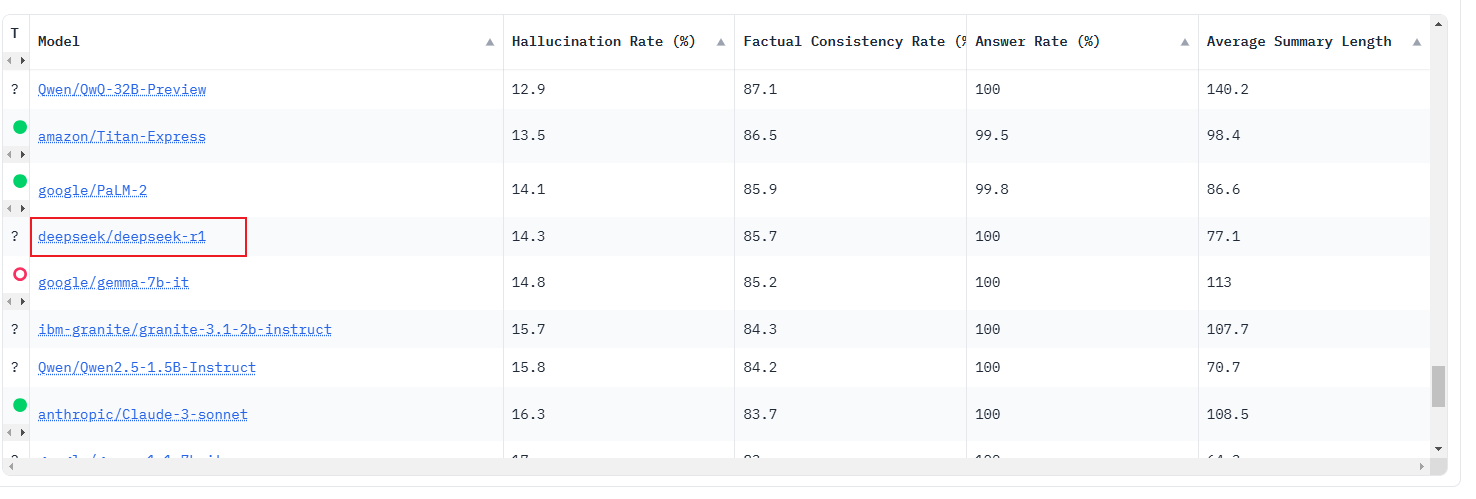
Deepseek R1 有超高的幻觉
在最新的 Hughes Hallucination Evaluation Model (HHEM) leaderboard 上,deepseek V3 的幻觉率达到 3.9%,而 deepseek-r1 高达 14.3%。(相对比 chatgpt o1 只有 2.4%)
在我的实际体验中,也发现,对于一些限定性的问题(比如文档摘要,根据 prd 输出测试用例)r1 的 Thinking 往往超出想要限定的范围,哪怕加上一些比如「请务必忠于原文」,其效果也不太好。
在一些不限定的区域,比如写诗歌、出方案,r1 有时候的结果让人很有思考。
所以,在实际体验中,我往往会采用两个方案:
-
针对不同的使用场景,分别选择推理或非推理模型(因地制宜)。
-
先用 r1 帮我整理思路,再用 v3 处理任务。
(榜单的前几名是: Gemini 2.0 flash 001 、openai/o3-mini-high-reasoning 、gemini-2.0-flash-exp)
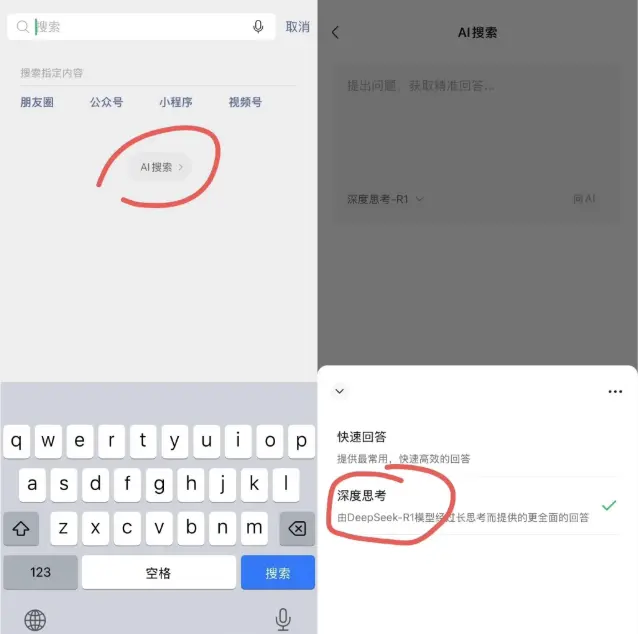
微信 AI 搜索接入 DeepSeek
微信最近在其搜索功能中灰度测试了 DeepSeek-R1 大模型的集成。用户可以在对话框顶部的搜索入口看到“AI 搜索”字样,点击后即可免费使用 DeepSeek-R1 模型,支持深度推理和快速回答。
目前,这一功能还处于灰度测试阶段,仅对部分用户开放。
微信的 AI 搜索结合了微信自身的大量数据和 DeepSeek-R1 的联网信息整合能力,预计将成为国内领先的 AI 搜索工具。
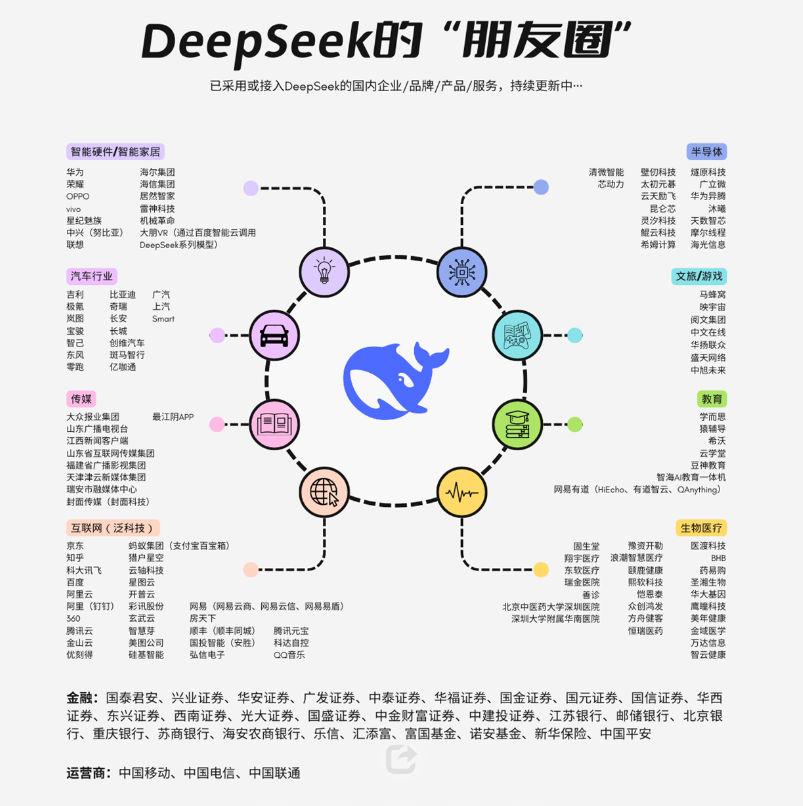
国内各行业,基本上都接入了Deepseek,以及在2月16日集中宣布



阿里开源 InspireMusic:专为音乐生成设计的 AIGC 工具包
InspireMusic 是阿里专为音乐、歌曲和音频生成而设计的 AIGC 工具包。
它支持通过文字描述和音乐特征精确控制生成的音乐风格和结构,并支持生成音乐、歌曲及其他音频内容。
目前模型已经开源,大家可以在线使用感受下,不过目前仅支持纯音乐生成,无法像 Suno 那样生成带人声的歌曲。

小红书开源 FireRedASR:支持普通话、方言和英文的语音识别模型
FireRedASR 是小红书开源的语音识别模型,支持识别普通话、方言和英文。它分为两个版本:
- FireRedASR-LLM:效果最佳,普通话识别开源领先,利用 LLM 处理语音数据。
- FireRedASR-AED:采用 AED 架构,兼顾效率和效果。
简单来说,FireRedASR 提供了两种不同的解决方案,一种追求极致的性能,另一种则在性能和效率之间找到平衡。目前代码和模型已经开源。
Perplexity 发布自己的 Deep Research 能力
把 Humanity’s Last Exam 测试刷到了 20.5% 的成绩
超过了现在发布的所有模型,仅次于 OpenAI 的 Deep Research 而且是免费提供的!
在生成结果的详细度上不如 Open AI 的,但是逻辑是在线的,并且能从搜索结果中推理得出一些结论 这份报告一共 2100 字,输出用了两分钟左右
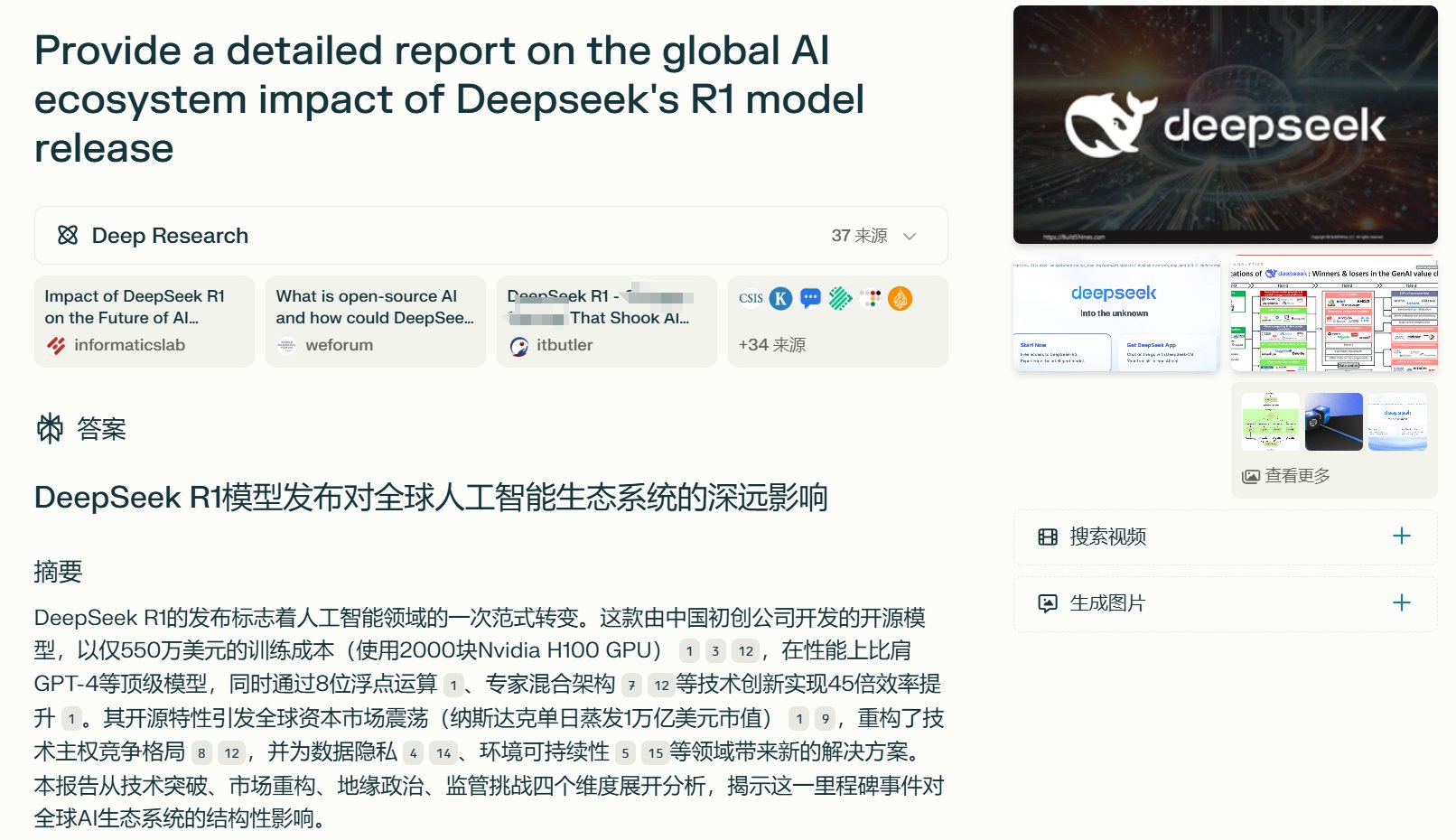
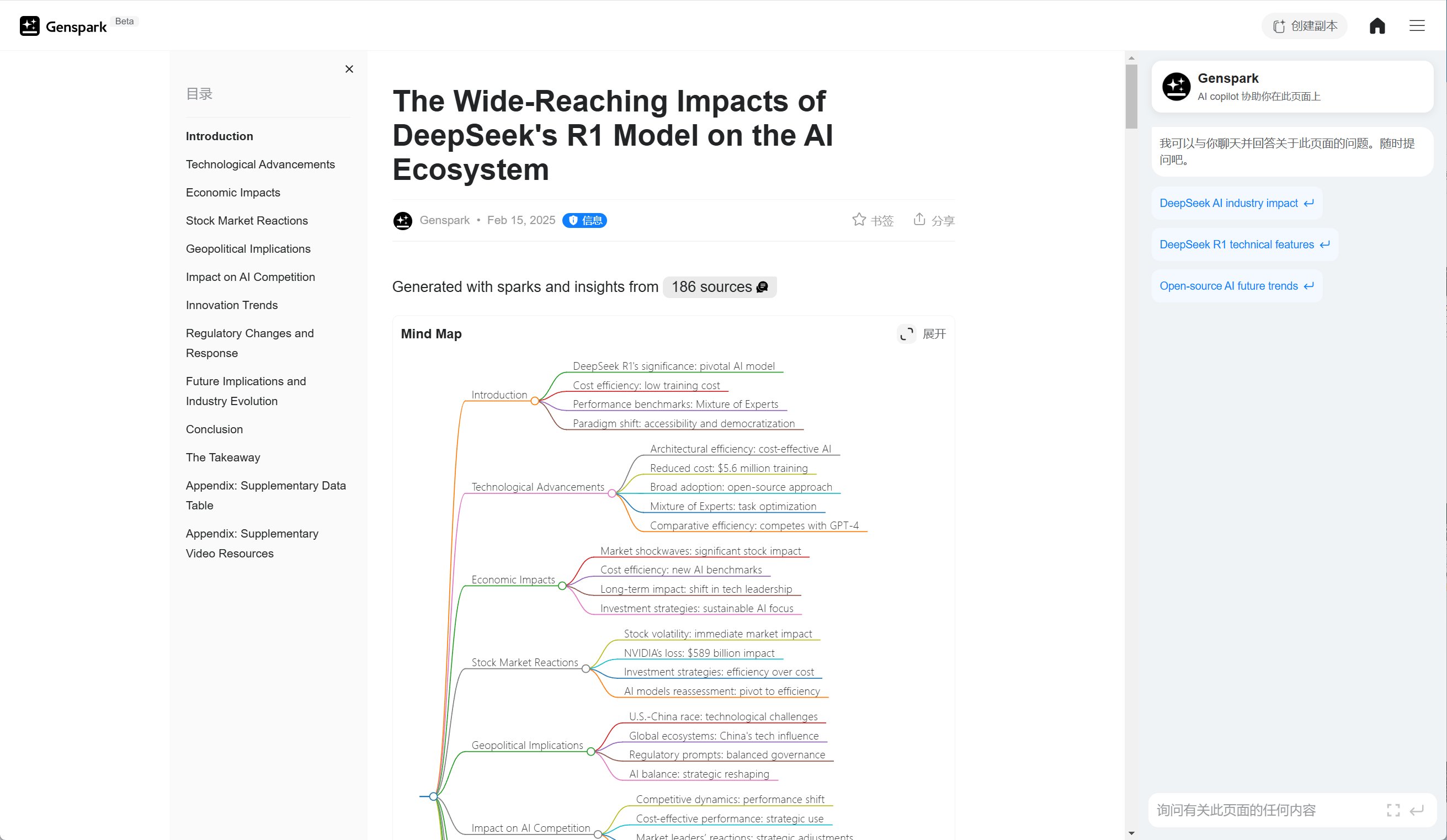
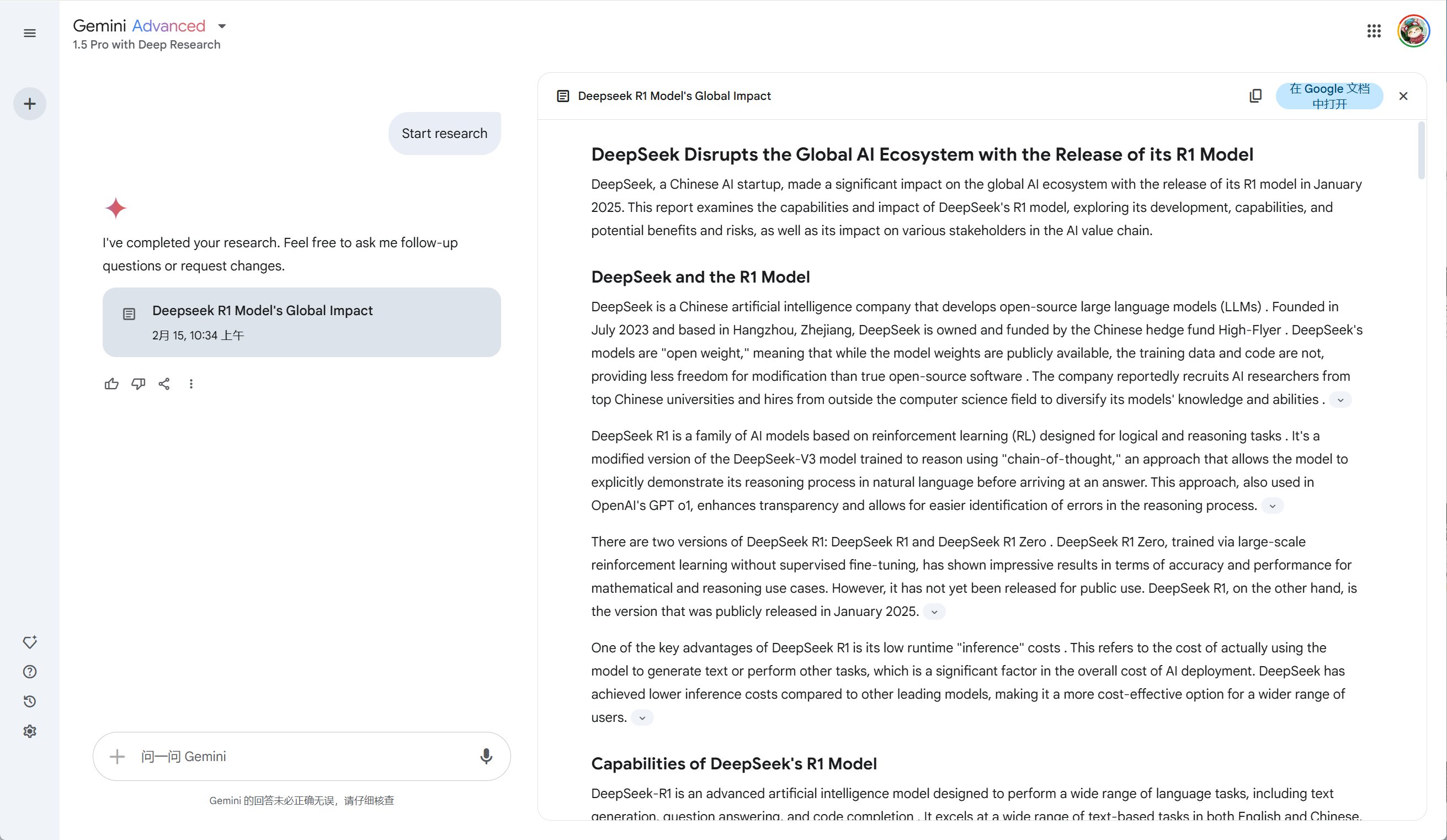
测试一下相同的问题下多个深度研究产品的答案
Perplexity Deep Research、秘塔深度研究、Genspark深度研究、Gemini 1.5 Pro Deep Research
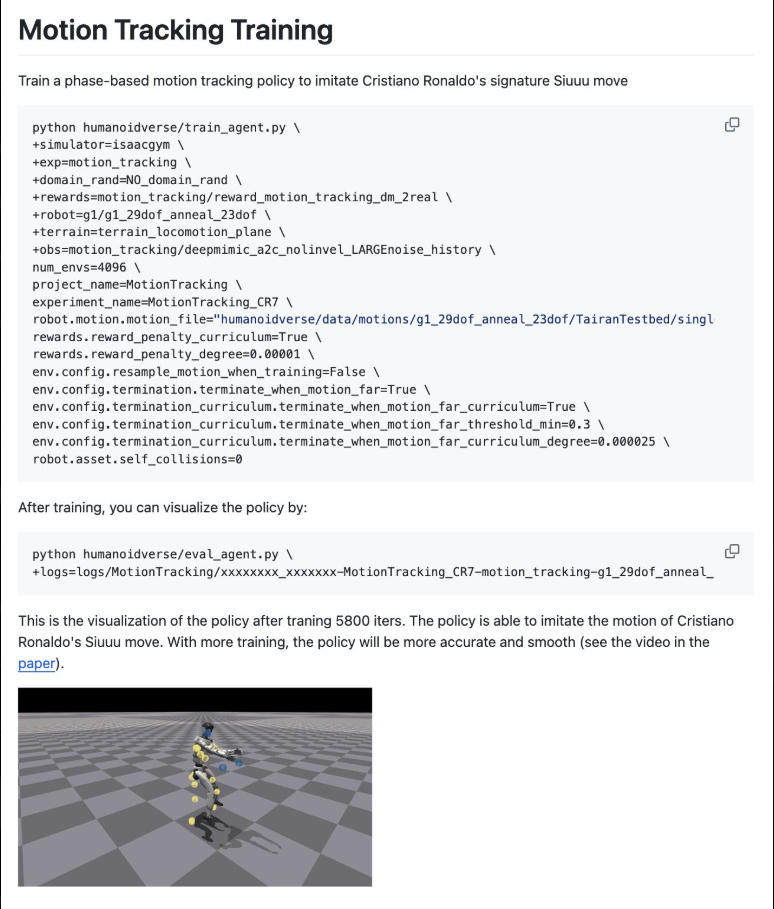
卡内基梅隆大学机器人博士生利用ASAP复制了克里斯蒂亚诺·罗纳尔多的标志性“Siuuu”跳跃!
我刚刚使用训练命令改进了开源 ASAP 代码( https://github.com/LeCAR-Lab/ASAP ),以便在两块 RTX 4090 GPU 上仅用 2 小时就复制了克里斯蒂亚诺·罗纳尔多的标志性“Siuuu”跳跃! 现在,你的人形机器人可以完成精英运动动作了